Welcome to My Blog!
这里记录着我的CV学习之路-
TTFNet
TTFNet
论文:Training-Time-Friendly Network for Real-Time Object Detection
代码链接: https://github.com/ZJULearning/ttfnet
主要贡献
本文就是针对CenterNet的小问题进行了改进,主要贡献就是极大的减少了训练时间,大概减少了7倍时长。
其核心思想是:从BBOX框中编码更多的训练样本,主要是增加高质量正样本数,与增加批量大小具有相似的作用,这有助于扩大学习速度并加快训练过程。主要是通过高斯核函数实现。其实很简单,我们知道centernet的回归分支仅仅在中心点位置计算loss,其余位置忽略,这种做法就是本文说的训练样本太少了,导致收敛很慢,需要特别长的训练时间,而本文采用高斯核编码形式,对中心点范围内满足高斯分布范围的点都当做正样本进行训练,可以极大的加速收敛。本文做法和FCOS非常类似,但是没有多尺度输出,也没有FPN等复杂结构。
作者首先做了一些证明:提供更多高质量的训练样本与增加批次大小具有类似的作用,可以提供更多的监督信号,从而加速收敛。
网络结构
和centernet差不多,使用了ResNet和DarkNet作为骨干,也是上采样到输入的1/4倍作为输出,区别是:为了减少小物体在下采样的时候丢失特征,引入了额外的挑层连接,类似Unet,假设高低层特征融合,可以有效缓解小物体精度较低的不足。
作者觉去掉了offset回归分支。目前只有两个分支输出,localization分支用于表示哪些区域有物体,和centernet里面含义相同,shape=(h/4,w/4,num_cls)。另一个是Regression分支,用于回归wh高,在centernet中,宽高回归分支的目标是基于中心点位置回归上距离,由于这种简单的设置,导致其只能在中心点位置才能计算loss,本文目的是增加正样本数,那么就不能采用这种目标编码方式了,本文采用的是FCOS的格式即回归的target是当前位置相对gt bbox的4条边的距离,故输出shape是(h/4,w/4,4)
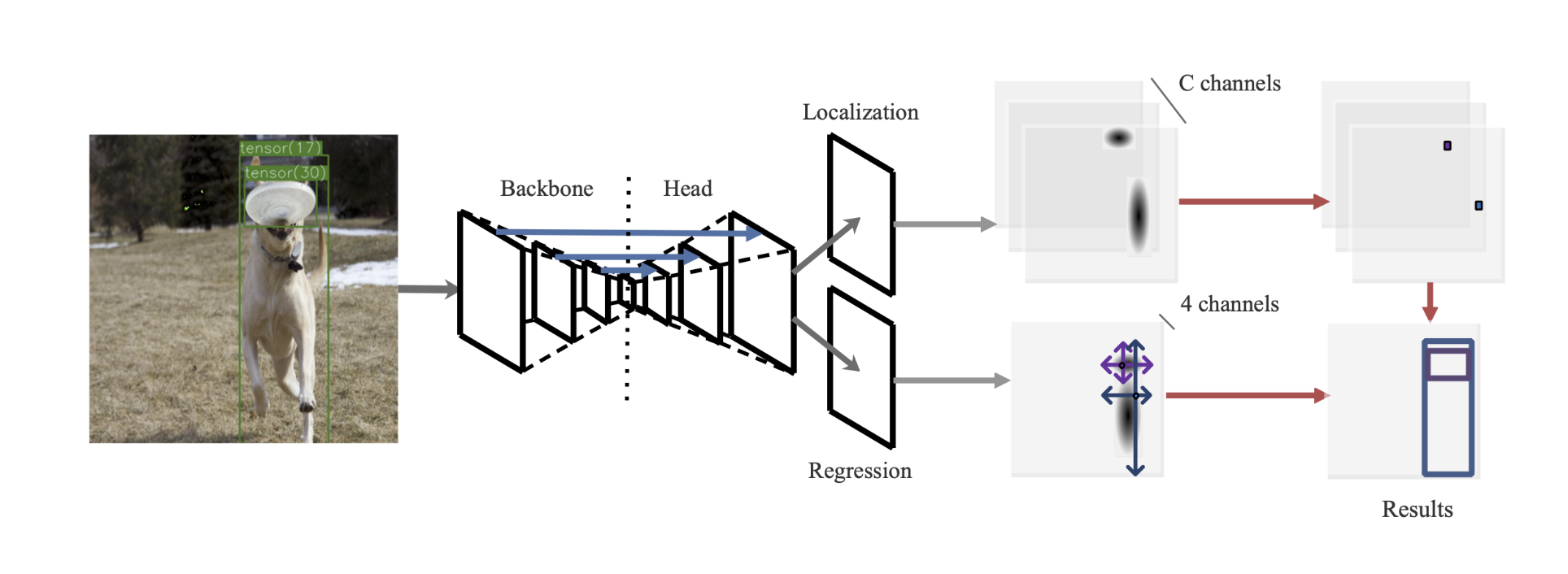
正负样本定义
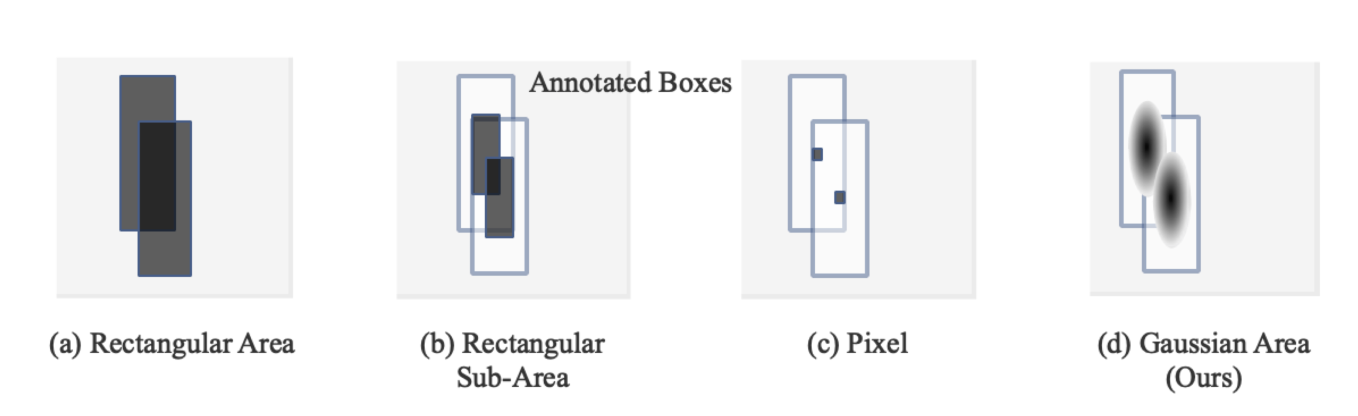
上图是一个直观的理解。假设图片中存在两个有交集的bbox,(a)是将bbox内部的所有区域都当做训练样本(一般就是值正样本),这种策略属于早期论文做法,现在基本不会这么做了;(b)是带shrink操作的样本定义方式,考虑bbox标注的不准确性,只考虑内部一定范围内的区域是训练样本,大部分anchor-free论文都是这种做法;(c)是centernet特有的做法,仅仅在中心点处才是训练样本,其余位置忽略;(d)是本文基于高斯核来定义确定训练样本区域。一眼看起来比其他三种更加科学。
(1) Object Localization 这个其实是分类分支,shape=(h/4,w/4,num_cls),label生成过程和centernet差不多,只不过centernet的高斯核是正方形核,而本文是椭圆形。
(2) Size Regression 其target不是和centernet一样,而是预测到4条边的距离,shape是(h/4,w/4,4)。训练样本区域和Object Localization一样,高斯核范围内的就是了。
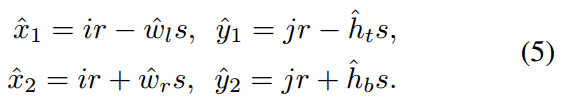
(ir,jr)是样本区域内的任意一点坐标,(w,h)是缩放了s倍,定义在特征图尺度的bbox的宽高值,对于任何一点其预测的bbox位置可以采用上述式子确定,也就是说,对于任意一点(ir,jr),网络预测输出是(wl,ht,wr,hb),注意这4个值是原图尺度,而不是特征图尺度哦!代表距离4条边的距离。这里的s不是stride=4,而是作者设置的16,目的是加快收敛。centernet回归wh时候是没有归一化的,本文也没有进行归一化,但是为了方便优化,对宽高预测分支乘上了s=16,缩小预测范围,训练更加稳定一些。有些算法会将这个s设置为可学习参数,目的都是一样的。
和FOCS一样,对于多个bbox重叠区域,其target是取最小bbox的标注。
Loss计算
该分支采用的回归loss是最新的GIOU,
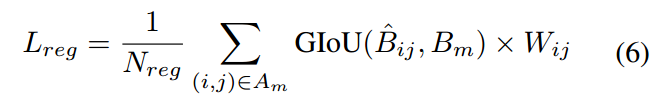
B是原图尺度的bbox坐标(xmin,ymin,xmax,ymax),是基于预测值进行解码还原后的bbox预测坐标。为了体现距离中心点远近,对loss的影响,引入了W权重。这个和FCOS的centerness分支左右差不多。
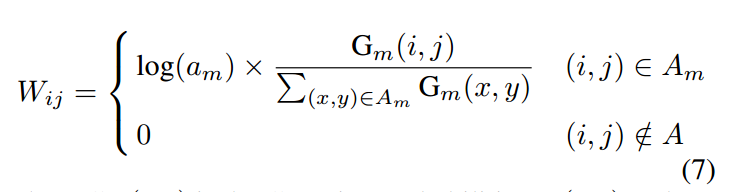
A是shrink后的矩形面积,G是前面得到的高斯核函数分布值,不考虑log(a)这一项,则就是简单的归一化加权而已,远距离的位置权重小,中心点附近权重大。而乘上log(a)则可以反映出bbox的大小属性了。
总的loss包括两个,一个是Object Localization,一个是Size Regression,权重设置比例为1:5。
-
CenterNet
CenterNet
论文名称:Objects as Points
代码链接:https://github.com/xingyizhou/CenterNet
主要贡献
构建模型时将目标作为一个点——即目标BBox的中心点。我们的检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸,3D位置,方向,甚至姿态。
第一,我们分配的锚点仅仅是放在位置上,没有尺寸框。没有手动设置的阈值做前后景分类。(像Faster RCNN会将与GT IOU >0.7的作为前景,<0.3的作为背景,其他不管);
第二,每个目标仅仅有一个正的锚点,因此不会用到NMS,我们提取关键点特征图上局部峰值点(local peaks);
第三,CenterNet 相比较传统目标检测而言(缩放16倍尺度),使用更大分辨率的输出特征图(缩放了4倍),因此无需用到多重特征图锚点;
网络结构
backbone
骨架网络采用了4种,分别是ResNet-18, ResNet-101, DLA-34和Hourglass-104。
head
对于目标检测而言,输出三个特征图,分别是高斯热图(h/4,w/4,cls_nums),每个通道代表一个类别;宽高输出图(h/4,w/4,2),代表对应中心点处预测的宽高;中心点量化偏移图(h/4,w/4,2),这个分支对于目标检测而言可能作用不会很大,因为我们最终要的是bbox,而不是中心点,但是对于姿态估计而言就非常重要了。
Loss计算
\[L=L_{k}+\lambda_{size} L_{size}+\lambda_{off} L_{off}\]
-
CornerNet
Cornernet
论文:CornerNet: Detecting Objects as Paired Keypoints,ECCV2018
代码链接:https://github.com/umich-vl/CornerNet
主要贡献
1、将目标检测问题当作关键点检测问题来解决,也就是通过检测目标框的左上角和右下角两个关键点得到预测框,没有anchor的概念。
2、整个检测网络的训练是从头开始的,并不基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。
常用的目标检测算法都是基于anchor的,但是引入anchor的缺点在于:1、正负样本不均衡。大部分检测算法的anchor数量都成千上万,但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及focal loss等算法来解决这个问题。2、引入更多的超参数,比如anchor的数量、大小和宽高比等。
网络结构
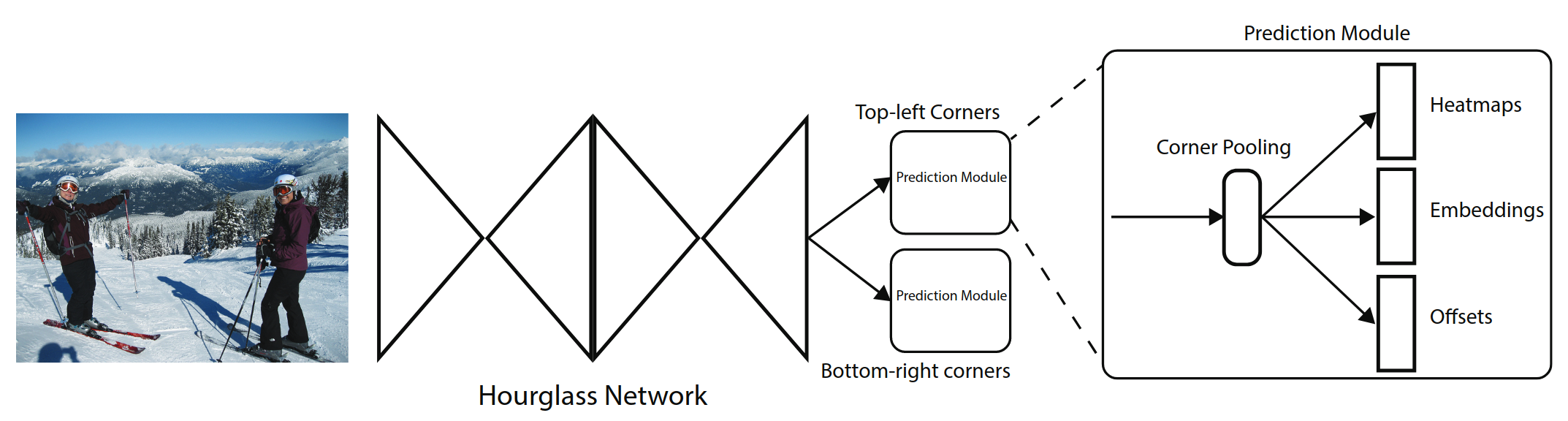
backbone
CornerNet 的基础网络结构采用hourglass类型的网络模块,连续堆叠了2个这样的模块。hourglass结构可以很好的结合局部特征和全局特征。在hourglass模块中没有使用pooling操作,而是使用stride=2的卷积实现下采样,这也可以获得更快的速度。最终feature map被缩小5倍。其中卷积层的通道数分别为(256; 384; 384; 384; 512)。hourglass结构的网络深度为104层。
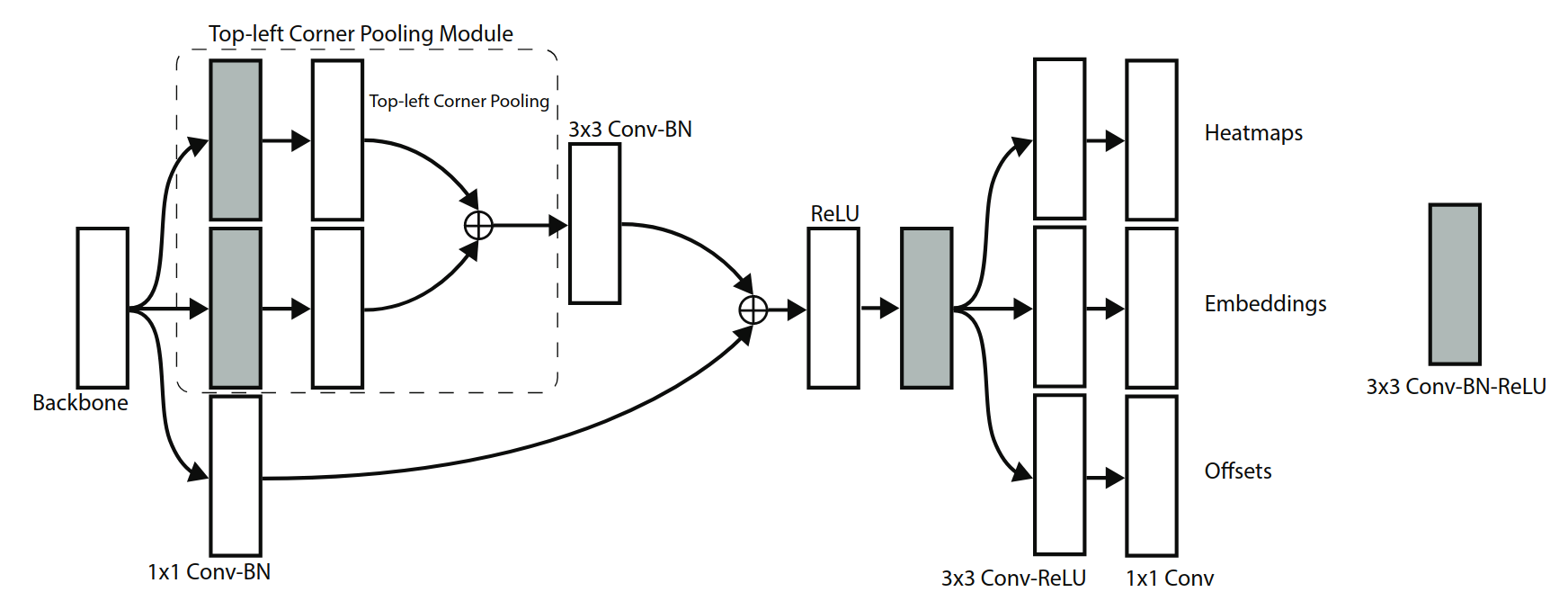
CornerNet 的检测模块如上图所示。上图只表示了top-left部分的结构,bottom-right也有类似的结构。经过backbone之后,首先经过corner pooling操作,输出pooling后的特征图,然后再和backbone的特征图做融合。相当于resnet中的shortcut结构在这里使用corner pooling替换。最终分为3个分支,分别输出heatmap,Embedding,offsets。网络最终top-left和bottom-right各输出一个heatmap为80x128x128、嵌入向量Embedding为1x128x128、偏移offsets为2x128x128。
传统的检测框架边框的位置是通过(x,y,width,height)确定的。而CornerNet的heatmap既包含边框的分数,还包含边框的位置。由于网络不断下采样会造成最终的坐标和原始图像的有偏移,这里采用了回归的offsets解决。至于左上角的点和右下角的点的配对,使用embedding来解决。
根据mmdetection上结构绘制网络结构图,hourglass有5层,hourglass两个输出均为256x128x128,共享cornerhead。
Loss计算
\[L=L_{det}+\alpha L_{pull}+\beta L_{push}+\gamma L_{off}\]heatmap部分损失函数:
\[L_{det}=\frac{-1}{N}\sum_{c=1}^{C}\sum_{i=1}^{H}\sum_{j=1}^{W}\left \{ \begin{array}{c} (1-p_{cij})^{\alpha}\log(p_{cij}) & \text{if } y_{cij}=1 \\ (1-y_{cij})^{\beta}(p_{cij})^{\alpha}\log(1-p_{cij}) & \text{otherwise} \end{array} \right.\]heatmap输出预测角点信息,维度为CxHxW,其中C表示目标的类别(没有背景类),这个特征图的每个通道都是一个mask,mask的范围为0到1(输出后经过sigmod),表示该点是角点的分数。$L_{det}$是GaussianFocalLoss是改良版的focal loss,$p_{cij}$表示预测的heatmap在第c个通道(i,j)位置的值,$y_{cij}$表示对应位置的ground truth,N表示目标的数量。$y_{cij}$的时候损失函数就是focal loss,$y_{cij}$为其他值表示该位置不是目标角点,按理为0(大部分算法这样处理的),但这里基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的$y_{cij}$值接近1,这部分通过$\beta$参数控制权重,这是和focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积。

高斯核半径r,为了满足iou>min_overlap,需满足以下条件,最后取min(r1, r2, r3)
Case1:一个角点在gt内部,一个在外部
\[\cfrac{(w-r)*(h-r)}{w*h+(w+h)r-r^2} \ge {iou} \quad\Rightarrow\quad {r^2-(w+h)r+\cfrac{1-iou}{1+iou}*w*h} \ge 0 \\ {a} = 1,\quad{b} = {-(w+h)},\quad{c} = {\cfrac{1-iou}{1+iou}*w*h}\\ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}\]Case2:两个角点都在gt内部
\[\cfrac{(w-2*r)*(h-2*r)}{w*h} \ge {iou} \quad\Rightarrow\quad {4r^2-2(w+h)r+(1-iou)*w*h} \ge 0 \\ {a} = 4,\quad {b} = {-2(w+h)},\quad {c} = {(1-iou)*w*h}\\ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}\]Case:两个角点都在gt外部
\[\cfrac{w*h}{(w+2*r)*(h+2*r)} \ge {iou} \quad\Rightarrow\quad {4*iou*r^2+2*iou*(w+h)r+(iou-1)*w*h} \le 0 \\ {a} = {4*iou},\quad {b} = {2*iou*(w+h)},\quad {c} = {(iou-1)*w*h} \\ {r} \le \cfrac{-b+\sqrt{b^2-4*a*c}}{2*a}\]2D高斯核函数$e^{-\frac{x^2+y^2}{2\sigma^2}}$,$\sigma$为(2*r+1)/6,叠加中心为角点位置,当两个同类目标交叠时,mask取最大值。
offset部分损失函数:
\[L_{off}=\frac{1}{N}\sum_{k=1}^{N}SmoothL1Loss(o_k,\hat{o_k})\\ o_k=(\frac{x_k}{n}-\left \lfloor \frac{x_k}{n}\right \rfloor,\frac{y_k}{n}-\left \lfloor \frac{y_k}{n}\right \rfloor)\]这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息。只计算角点位置损失。
embedding部分损失函数:
\[L_{pull}=\frac{1}{N}\sum_{k=1}^{N}[(e_{t_{k}}-e_k)^2+(e_{b_{k}}-e_k)^2]\\ L_{push}=\frac{1}{N(N-1)}\sum_{k=1}^{N}\sum_{j=1\\j\neq k}^{N}max(0,\Delta-\left |e_k-e_j \right |)\]$e_{t_{k}}$表示第k个目标的左上角角点的embedding vector,$e_{b_{k}}$表示第k个目标的右下角角点的embedding vector,$e_{k}$表示$e_{t_{k}}$和$e_{b_{k}}$的均值,$L_{pull}$用来缩小属于同一个目标(第k个目标)的两个角点的embedding vector(etk和ebk)距离,$L_{push}$用来扩大不属于同一个目标的两个角点的embedding vector距离。
Corner pooling
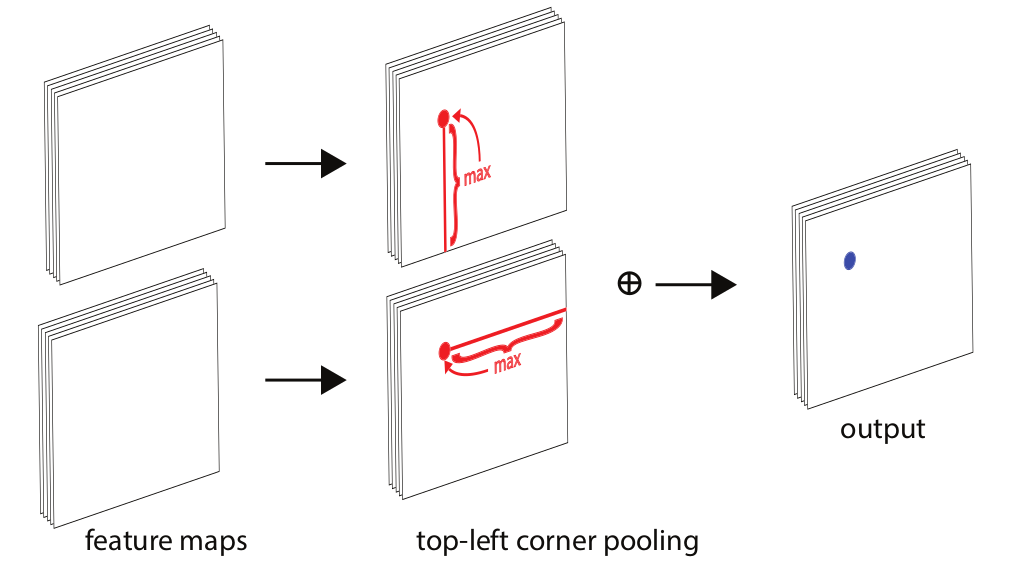
因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息,左上角角点的下边有目标左侧的特征信息,因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。
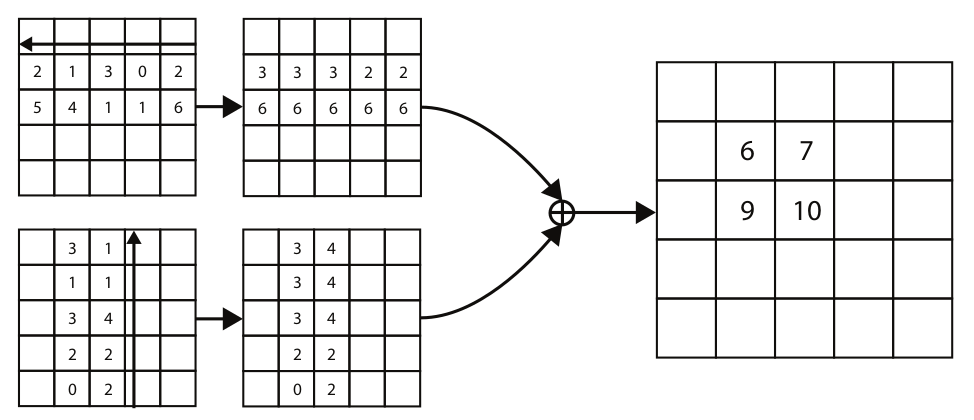
下图是针对左上角点做corner pooling,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值;同时计算(i,j)到(W,j)的最大值,然后将这两个最大值相加得到(i,j)点的值。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。(torch实现torch.cummax+flip)
推理流程
1、在得到预测角点后,会对这些角点做NMS操作,选择前100个左上角角点和100个右下角角点。
2、计算左上角和右下角角点的embedding vector的距离时采用L1范数,距离大于0.5或者两个点来自不同类别的目标的都不能构成一对。
3、测试图像采用0值填充方式得到指定大小作为网络的输入,而不是采用resize,另外同时测试图像的水平翻转图并融合二者的结果。
4、最后通过soft-nms操作去除冗余框,只保留前100个预测框。
优化方向
对box的坐标、尺寸和类别的预测只依赖对象的边缘特征,并没有使用对象内部的特征,这样的话会预测很多False Positive box
-
FCOS
FCOS
论文名称: FCOS: A simple and strong anchor-free object detector
论文名称: FCOS: Fully Convolutional One-Stage Object Detection
主要贡献
FCOS是目前最经典优雅的一阶段anchor-free目标检测算法,其模型结构主流、设计思路清晰、超参极少和不错的性能使其成为后续各个改进算法的baseline,和retinanet一样影响深远。
anchor-base的缺点是:超参太多,特别是anchor的设置对结果影响很大,不同项目这些超参都需要根据经验来确定,难度较大。 而anchor-free做法虽然还是有超参,但是至少去掉了anchor设置这个最大难题。fcos算法可以认为是point-base类算法也就是特征图上面每一个点都进行分类和回归预测,简单来说就是anchor个数为1的且为正方形anchor-base类算法。
网络结构
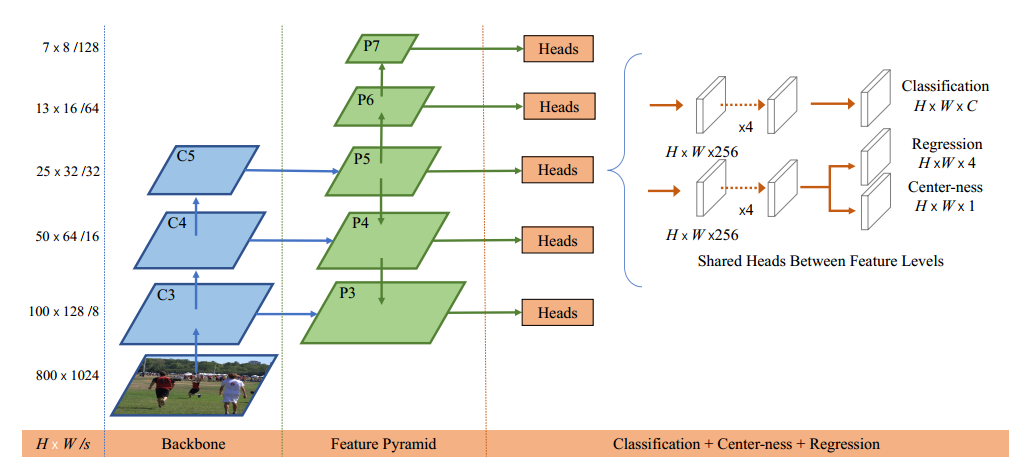
fcos和retinanet网络相似
backbone
retinanet在得到p6,p7的时候是采用c5层特征进行maxpool得到的,而fcos是从p5层抽取得到的,而且其p6和p7进行卷积前,还会经过relu操作,retinanet的FPN没有这个算子(C5不需要是因为resnet输出最后就是relu)。
head
和retinanet相比,fcos的head结构多了一个centerness分支,其余也是比较重量级的两条不共享参数的4层卷积操作,然后得到分类和回归两条分支。fcos是point-base类算法,对于特征图上面任何一点都回归其距离bbox的4条边距离,由于大小bbox且数值问题,一般都会对值进行变换,也就是除以s,主要目的是压缩预测范围,容易平衡分类和回归Loss权重。如果某个特征图上面点处于多个bbox重叠位置,则该point负责小bbox的预测。
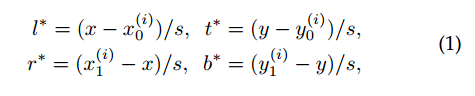
正负样本定义
(1) 对于任何一个gt bbox,首先映射到每一个输出层,利用center_sampling_ratio值计算出该gt bbox在每一层的正样本区域以及对应的left/top/right/bottom的target (2) 对于每个输出层的正样本区域,遍历每个point位置,计算其max(left/top/right/bottom的target)值是否在指定范围内regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),不再范围内的认为是背景
CNN对尺度是非常敏感的,一个层负责处理各种尺度,难度比较大,采用FPN来限制回归范围可以减少训练难度
loss计算
对于分类分支其采用的是FocalLoss,参数和retinanet一样。对于回归分支其采用的是GIou loss。在这种设置情况下,作者发现训推理时候会出现一些奇怪的bbox,原因是对于回归分支,正样本区域的权重是一样的,同等对待,导致那些虽然是正样本但是离gt bbox中心比较远的点对最终loss产生了比较大的影响,其实这个现象很容易想到,但是解决办法有多种。作者解决办法是引入额外的centerness分类分支,该分支和bbox回归分支共享权重,仅仅在bbox head最后并行一个centerness分支,其target的设置是离gt bbox中心点越近,该值越大,范围是0-1。虽然这是一个回归问题,但是作者采用的依然是ce loss。
越靠近中心,min(l,r)和max(l,r)越接近1,也就是越大。
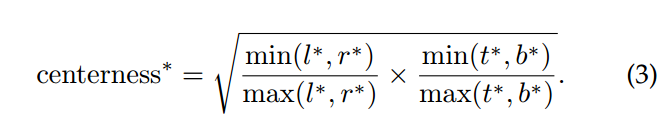
附加内容
fcos代码在第一版和最终版上面修改了很多训练技巧,对最终mAP有比较大的影响,主要是:
pr(1) centerness 分支的位置 早先是和分类分支放一起,后来和回归分支放一起 (2) 中心采样策略 早先版本是没有中心采样策略的 (3) bbox预测范围 早先是采用exp进行映射,后来改成了对预测值进行relu,然后利用scale因子缩放 (4) bbox loss权重 早先是所有正样本都是同样权重,后来将样本点对应的centerness target作为权重,离GT中心越近,权重越大 (5) bbox Loss选择 早先采用的是iou,后面有更优秀的giou,或许还可以尝试ciou (6) nms阈值选取 早先版本采用的是0.5,后面改为0.6
-
RetinaNet
Retinanet
RetinaNet算法源自2018年Facebook AI Research的论文 Focal Loss for Dense Object Detection。
主要贡献
(1) 深入分析了何种原因导致one-stage检测器精度低于two-stage检测器 。
(2) 针对上述问题,提出了一种简单但是极其实用的Focal Loss焦点损失函数用于解决类别不平衡、挖掘难分样本,并且focal思想可以推广到其他领域 。
(3) 针对目标检测特定问题,专门设计了一个RetinaNet网络,结合Focal Loss使得one-stage 检测器在精度上能够达到乃至超过two-stage检测器,在速度上和一阶段相同。
网络结构
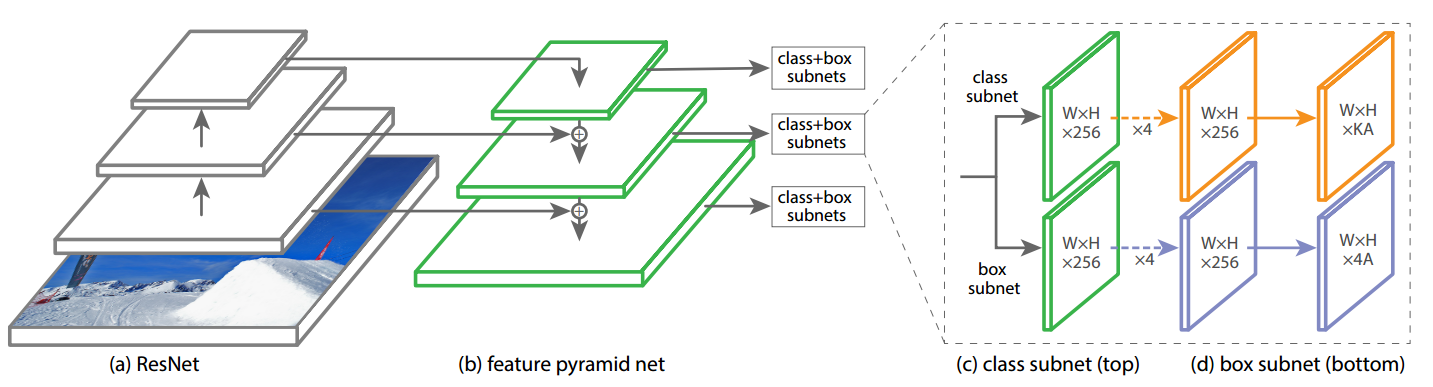
retinanet非常经典,包括骨架resnet+FPN层+输出head,一共包括5个多尺度输出层。
backbone
resnet输出是4个特征图,按照特征图从大到小排列,分别是c2 c3 c4 c5,stride=4,8,16,32。Retinanet考虑计算量仅仅用了c3 c4 c5。
neck
neck模块是标准的FPN结构,其作用是特征融合,其细节是:先对这c3 c4 c5三层进行1x1改变通道,全部输出256个通道;然后经过从高层到底层的最近邻2x上采样+add操作进行特征融合,最后对每个层进行3x3的卷积,得到p3,p4,p5特征图。
还需要构建两个额外的输出层stride=64,128,首先对c5进行3x3卷积且stride=2进行下采样得到P6,然后对P6进行同样的3x3卷积且stride=2,得到P7。
整个FPN层都不含BN和relu
head
retinanet的head模块比较大,其输出头包括分类和检测head两个分支,且每个分支都包括4个卷积层,不进行参数共享,分类head输出通道是num_class * K,检测head输出通道是4 * K,K是anchor个数。虽然每个head的分类和回归分支权重不共享,但是5个输出特征图的head是权重共享的。
正负样本定义
retinanet采用了密集anchor设定规则,每个输出特征图位置都输出K=9个anchor,非常密集。
匹配策略非常简单就是MaxIoUAssigner,大意是:
- 初始所有anchor都定义为忽略样本 。
- 遍历所有anchor,每个anchor和所有gt的最大iou小于0.4,则该anchor是背景 。
- 遍历所有anchor,每个anchor和所有gt的最大iou大于0.5,则该anchor是正样本且最大iou对应的gt是匹配对象 。
- 遍历所有gt,每个gt和所有anchor的最大iou大于0,则该对应的anchor也是正样本,负责对于gt的匹配,可以发现min_pos_iou=0 表示每个gt都一定有anchor匹配,且会出现忽略样本,可能引入低质量anchor。
anchor_generator=dict( type='AnchorGenerator', # 每层特征图的base anchor scale,如果变大,则整体anchor都会放大 octave_base_scale=4, # 每层有3个尺度 2**0 2**(1/3) 2**(2/3) scales_per_octave=3, # 每层的anchor有3种长宽比 故每一层每个位置有9个anchor ratios=[0.5, 1.0, 2.0], # 每个特征图层输出stride,故anchor范围是4x8=32,4x128x2**(2/3)=812.7 strides=[8, 16, 32, 64, 128]),每个尺度的anchor计算方法
\[base\_scale=4\\ base\_size=[8,16,32,64,128]\\ scales=[2^0,2^{1/3},2^{2/3}]*base\_scale\\ ratios=[1/2,1,2]\\ h\_ratios=\sqrt{ratios}\\ w\_ratios=1/\sqrt{ratios}\\ hs=base\_size[i]*h\_ratios*scale\\ ws=base\_size[i]*w\_ratios*scale\\ base\_anchors = [\\x\_center - 0.5 * ws, y\_center - 0.5 * hs,\\ x\_center + 0.5 * ws,y\_center + 0.5 * hs]\]#双阈值策略 assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.4, min_pos_iou=0, ignore_iof_thr=-1),bbox编解码
为了使得各分支Loss更加稳定,需要对gt bbox进行编解码,其编解码过程也是基于gt bbox和anchor box的中心偏移+宽高比规则DeltaXYWHBBoxCoder大意是:
- 特征图每个位置生成9个anchor与gt计算iou,经过阈值筛选得到匹配的anchor以及对应的gt。
- 将匹配anchor与对应gt转换成中心及宽高形式,计算$dx,dy,dw,dh$。
dx = (gx - px) / pw dy = (gy - py) / ph dw = torch.log(gw / pw) dh = torch.log(gh / ph)loss计算
虽然正负样本定义阶段存在极度不平衡,但是由于focal loss的引入可以在很大程度克服。故分类分支采用focal loss,回归分支可以采用l1 loss或者smooth l1 loss,实验效果表明l1 loss好一些。
loss_cls=dict( type='FocalLoss', use_sigmoid=True, gamma=2.0, alpha=0.25, loss_weight=1.0), loss_bbox=dict(type='L1Loss', loss_weight=1.0)))Focal Loss
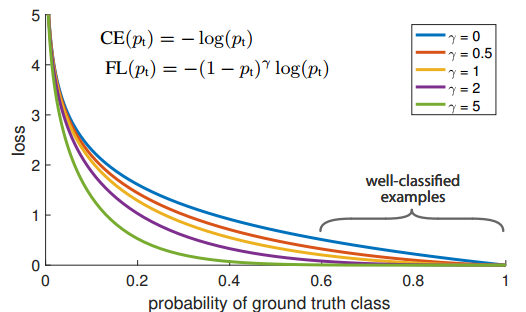
FL本质上解决的是将大量易学习样本的loss权重降低,但是不丢弃样本,突出难学习样本的loss权重,但是因为大部分易学习样本都是负样本,所以还有一个附加功能即解决了正负样本不平衡问题。其是根据交叉熵改进而来,本质是dynamically scaled cross entropy loss,直接按照loss decay掉那些easy example的权重,这样使训练更加bias到更有意义的样本中去,说通俗点就是一个解决分类问题中类别不平衡、分类难度差异的一个loss。
注意上面的公式表示label必须是one-hot形式。只看图示就很好理解了,对于任何一个类别的样本,本质上是希望学习的概率为1,当预测输出接近1时候,该样本loss权重是很低的,当预测的结果越接近0,该样本loss权重就越高。而且相比于原始的CE,这种差距会进一步拉开。由于大量样本都是属于well-classified examples,故这部分样本的loss全部都需要往下拉。 \(FL=-\alpha_t(1-p_t)^\gamma log(p_t)\)
bias初始化
在Retinanet中,其分类分支初始化bias权重设置非常关键。$b=-\log(\frac{1-\pi}{\pi}),\pi=0.01$,这个操作非常关键,原因是anchor太多,负样本远远大于正样本,也就是说分类分支,假设负样本:正样本数=1000:1。分类是sigmod输出,其输出的负数表示负样本label,如果某个batch的分类输出都是负数,那么也就是预测全部是负类,这样算loss时候就会比较小,相当于强制输出的值偏向负类。许多anchor free方法也是用的改进的高斯FL,所以也是用的BCE。
推理流程
在推理阶段,对5个输出head的预测首先取topK的预测值,然后用0.05的阈值过滤掉背景,此时得到的检测结果已经大大降低,此时再对检测结果的box分支进行解码,最后把输出head的检测结果拼接在一起,通过IoU=0.5的NMS过滤重叠框就得到最终结果。
-
YOLO系列
YOLO系列
YOLOv1论文:You Only Look Once: Unified, Real-Time Object Detection
YOLOv2论文:YOLO9000:Better, Faster, Stronger
YOLOv3论文:Yolov3: An Incremental Improvement
YOLOv4论文:Yolov4: Optimal Speed and Accuracy of Object Detection
来源参考
YOLOv1
主要贡献:提出了一个极度简单、通用、思路清晰、速度和精度平衡的目标检测算法。不需要复杂的两阶段refine思想,一次性即可学习出图片中所有目标类别和坐标信息,算是one-stage目标检测的先行者。
网络结构
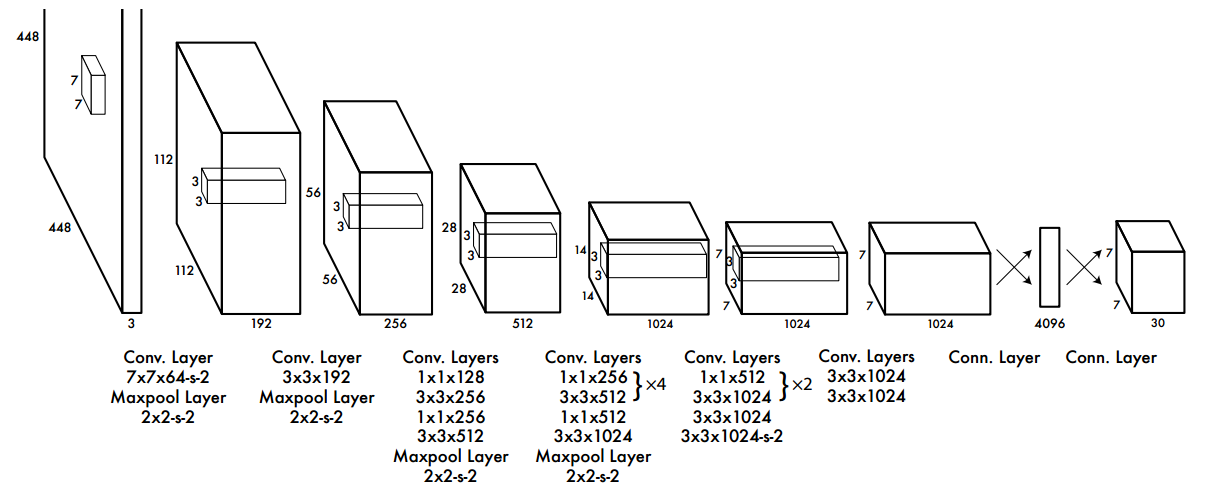
设计的骨架比较简单,就是标准卷积+池化的直筒结构。卷积层后面的激活函数是 Leaky ReLU 。
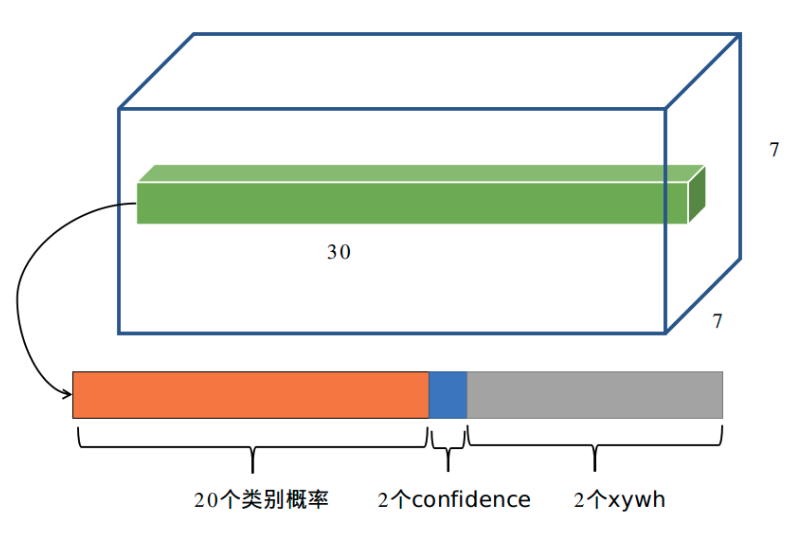
最后一层是采用fc形式输出,没有激活函数,shape为(batch,S×S×(B*5+C),S是网格参数,B是每个网格输出的bbox个数,C是类别数,5是表示bbox的xywh预测值加上一个置信度预测值。对于VOC数据且输入是448x448,S=7,B=2,则输出是(batch,7x7x(2*(4+1)+20))=(batch,7x7x30)。
前20个数是不包括背景的类别信息,值最大的索引就是对应类别;由于B=2,所以前2个数是置信度分支;后面2x4个数按照xywhxywh的格式存储。
置信度分值反映了模型对于这个网格的预测,包括两个信息:该网格是否含有物体,以及这个bbox的坐标预测有多准。值越大表示越可能有前景物体,且该网格的预测bbox越准确。是否可以舍弃置信度预测值,只预测类别和位置?答案是:如果仅仅考虑该网格是否含有物体的作用,那么完全可以舍弃,把这个功能并入分类分支即可(cls_num+1,1是背景类别),但是如果还要同时考虑预测bbox准确度,那么就不能舍弃,否则无法实现这个功能。
在强行施加了网格限制以后,每个网格最多只能输出一个预测结果(不管B设置为多少都一样,需要知道正样本定义规则才能理解),所以该算法最大不足是理论召回率比较低,特别是在物体和物体靠的比较近且物体比较小的时候,很大几率多个物体中心坐标会落在同一个网格中,导致漏检。
正负样本定义
对于任何一个gt bbox,如果其中心坐标落在某个网格内部,那么该网格就负责预测该物体。
有一个细节需要注意:B=2也就是每个网格要预测两个bbox,将B个xywh预测值都进行解码还原为预测bbox格式,然后计算B个预测bbox和对应gt bbox的iou,哪个iou大就哪个xywh预测框负责预测该gt bbox,另一个当做负样本。那么如果某个网格有m(m>=2)个gt bbox中心落在里面,匹配规则是将B个预测bbox和所有gt bbox计算iou,然后取最大iou就可以找到哪个预测框和哪个gt bbox最匹配,此时该预测框就是正样本,其余全部算负样本,其余gt bbox被忽略当做背景处理。
bbox编解码
理论上每个网格的xywh预测值可以是gt bbox的真实值,但是这样做不太好,因为xy和wh的预测范围不一样,并且分类和bbox预测分支取值范围也不一样,如果不做任何设计会出现某个分支训练的好而其余分支训练的不好现象,效果可能不太好,所以对bbox进行编解码是非常关键的。
对于xy预测值的target,其表示gt bbox中心相当于所负责网格左上角的偏移,范围是0~1。假设该gt bbox的中心坐标为(200,300),图片大小是448x448,S=7,那么其xy label计算过程是:
- 将gt bbox中心坐标值映射到特征图上,其实就是除以stride=448/7=64,得到(200/64=3.125,300/64=4.69)
- 然后向下取整得到所负责该gt的网格坐标(3,4)
- 计算xy值label=(0.125,0.69)
对于wh预测就直接将gt bbox的宽高除以图片宽高归一化即可,其范围也是0~1。这个操作本身没有问题,但是其忽略了大小bbox属性,会出现小物体梯度比较小的问题出现漏检,作者做法是采用平方根变换。其本质是压缩大小物体回归差距,使得大小不同尺度物体在loss层面相同时候更加重视小物体。
loss设计
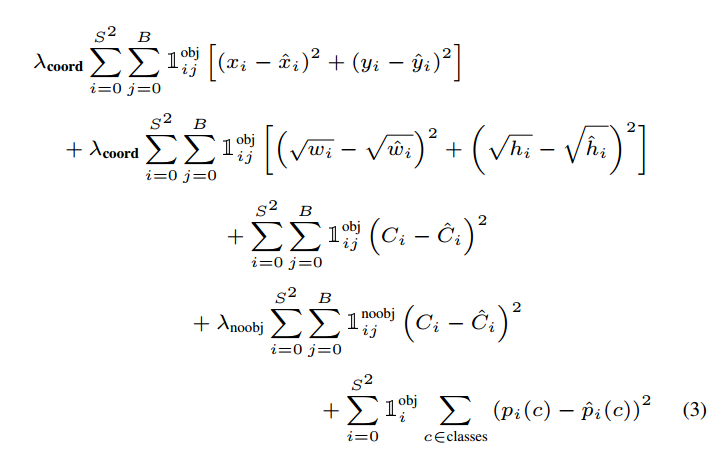
所有loss都是L2 loss即都是回归问题,并且因为是回归问题,所以即使xywh预测范围是0~1也没有采用sigmoid进行强制压缩范围(原因是sigmoid有饱和区)。
- 对于xywh向量,其仅仅计算正样本loss,其余位置是忽略的
- 对于类别向量,其也是仅仅计算正样本loss,其余位置是忽略的,label向量是One-hot编码
- 对于置信度值,其需要考虑正负样本,并且正负样本权重不一样。特别的为了实现置信度值的功能:该网格是否含有物体,以及这个box的坐标预测的有多准,对于正样本,其置信度的label不是1,而是预测bbox和gt bbox的iou值,对于负样本,其置信度label=0。当然如果你希望置信度值仅仅具有该网格是否含有物体功能,那么只需要正样本label设置为1即可,代码实现上通过变量rescore控制。
因为正样本非常少,故其设置了$\lambda_{noobj}=0.5,\lambda_{coord}=5$,参数来平衡正负样本梯度。
推理流程
(1) 遍历每个网格,将B个置信度预测值和预测类别向量分值相乘,得到每个bbox的类相关置信度值,可以发现这个乘积即表示了预测的bbox属于某一类的概率和该bbox准确度的信息,此时一共有SXSXB个预测框 (2) 设置阈值,滤掉类相关置信度值低的boxes,同时将剩下的bbox还原到原图尺度,xy中心坐标还原是首先加上当前网格左上角坐标,然后乘上stride即可,而wh值就直接乘上图片wh即可 (3) 对剩下的boxes进行NMS处理,就得到最终检测结果
总结
YOLO可以说是第一个简洁优美的one-stage目标检测算法,设计思路非常简洁清晰,最大优点是速度极快、背景误检率低,缺点是由于网格特点召回率会低一些,回归精度也不是很高,特别是小物体,这些缺点在后续的YOLOv2-v3中都有极大改善。
YOLOv2
主要贡献:对YOLOv1进行改进,大幅提升了定位准确度和召回率,同时速度也是极快。
trick:
-
batch norm:BN的作用主要是加快收敛,避免过拟合
-
new network:提出darknet19
-
全卷积形式:YOLOv1采用全连接层输出学习适应不同物体的形状比较困难(本身cnn就不具有尺度不变性)导致YOLOv1在精确定位方面表现较差。
-
anchor bbox:n个anchor bbox,提高召回率,可以真正实现每个网格预测多个物体。 但是训练策略依然采用的是YOLOv1中的,正负样本不平衡问题应该是加剧了导致mAP稍有下降。
-
dimension priors:anchor kmean自动聚类算法
-
passthrough:在head部分所提的从高分辨率特征图变成低分辨率特征图的特征融合操作
ssd是完全基于iou阈值进行匹配,只要anchor设置和iou阈值设置合适就可以保证正样本比较多,会更稳定。而yolo匹配策略仅仅是每个gt bbox一定匹配唯一的anchor,不管你anchor设置的如何,其正样本非常少,前期训练肯定更加不稳定。
网络结构
backbone
引入BN层、新的骨架网络darknet19,每个convolutional都包括conv+bn+leakyrelu模块,和vgg相同的直筒结构。
head
假设网络输入大小是416x416,那么骨架网络最后层输出shape为(b,1024,13,13),也就是说采用固定stride=32。如果直接在骨架网络最后一层再接几个卷积层,然后进行预测完全没有问题。作者认为13x13的特征图对于大物体检测来说是够了,但是对于小物体,特征图提供的信息就不一定够了,很可能特征已经消失了,故作者结合特征融合思想,提出一种新的passthrough层来产生更精细的特征图,本质上是一种特征聚合操作,目的是增强小物体特征图信息。
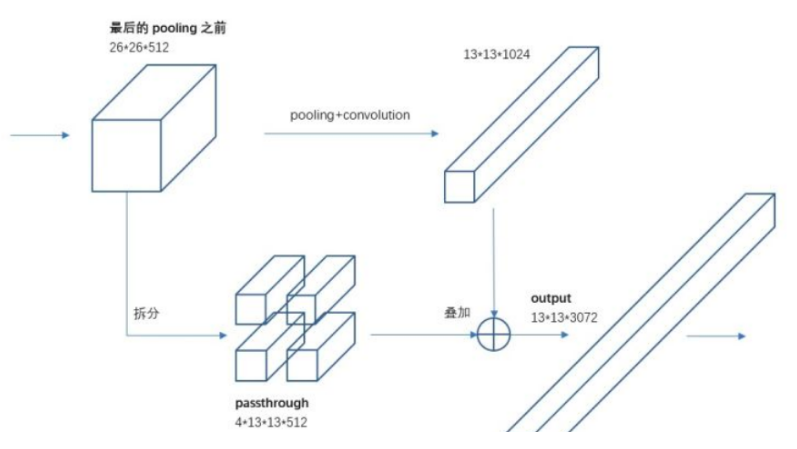
上面的第一个输入箭头是darknet-19的最后一个max pool运行前的特征图,假设图片输入是416x416,那么最后一个max pool层输入尺度为26x26x512,在该层卷积输出后引入一个新的分支:passthrough层,将原来尺度为26x26x512特征图拆分13x13x2048的特征图,然后和darkent-19骨架最后一层卷积的13x13x1024特征图进行concat,得到13x13x3072的特征图,然后经过conv+bn+leakyrelu,得到最终的预测图。上面的图通道画的不对,实际上由于通道太大了,消耗内存太多,故作者实际上做法是先将26x26x512降维为26x26x64,然后拆分为13x13x256,concat后,得到13x13x1280的特征图。
正负样本定义
(1) 正负属性定义 在设定anchor后就需要对每个anchor位置样本定义正负属性了。其规则和yolov1一样简单:保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大。具体就是:对于某个gt bbox,首先要确定其中心点要落在哪个网格内,然后计算这个网格的5个anchor与该gt bbox的IOU值,计算IOU值时不考虑坐标,只考虑形状(因为此处anchor没有坐标xy信息),所以先将anchor与gt bbox的中心点对齐(简单做法就是把anchor的xy设置为gt bbox的中心点即可),然后计算出对应的IOU值,IOU值最大的那个anchor与gt bbox匹配,对应的预测框用来预测这个gt bbox。其余anchor暂时算作负样本。
有1个情况需要思考清楚:假设有2个gt bbox的中心都落在同一个网格,且形状差异较大,此时这2个gt bbox应该会匹配到不同的anchor,这是我们希望的。但是如果差异比较小,导致都匹配上同一个anchor了,那么后一个gt bbox会把前一个gt bbox匹配的anchor覆盖掉,导致前面的gt bbox变成负样本了,这就是常说的标签重写问题。
上述匹配规则在不同复现版本里面有不同实现(官方代码也有,但是从来没有开启该设置),基于上述匹配规则并且借鉴ssd的做法,可以额外加上一个匹配规则:当每个gt bbox和最大iou的anchor匹配完成后,对剩下的anchor再次和对应网格内的gt bbox进行匹配(必须限制在对应网格内,否则xy预测范围变了),当该anchor和gt bbox的iou大于一定阈值例如0.7后,也算作正样本,即该anchor也负责预测gt bbox。这样的结果就是一个gt bbox可能和好几个anchor匹配,增加了正样本数,理论上会更好。
(2) 忽略属性定义 此时已经确定了所有anchor所对应的正负属性了,但是我们可以试图分析一种情况:假设某个anchor的预测bbox和某个gt bbox的iou为0.8,但是在前面的匹配策略中认为其是负样本,这是非常可能出现的,因为每个gt bbox仅仅和一个anchor匹配上,对于其附近的其余anchor强制认为是负样本。此时由于该负样本anchor预测的情况非常好,如果强行当做负样本进行训练,给人感觉就是不太对劲,但是也不能当做正样本(因为匹配规则就是如此设计的),此时我们可以把他当做灰色地带的样本也就是忽略样本,对这类anchor的预测值不计算loss即可,让他自生自灭吧!
故作者新增了忽略样本这个属性(算是yolo系列正负样本定义的一个特色吧),具体计算过程是:遍历每个anchor的预测值,如果anchor预测值和其余所有gt bbox的所有iou值中,只要有一个iou值大于阈值(通常是0.6),则该anchor预测值忽略,不计算loss,对中间灰色区域就不管了,保证学习的连续性。
归纳:
- 遍历每个gt bbox,首先判断其中心点落在哪个网格,然后和那个网格内的所有anchor计算iou,iou最大的anchor就负责匹配即正样本
- 考虑额外规则:当每个gt bbox和最大iou的anchor匹配完成后,对剩下的anchor再次和对应网格内的gt bbox进行匹配(必须限制在对应网格内,否则xy预测范围变了),当该anchor和gt bbox的iou大于一定阈值例如0.7后,也算作正样本,即该anchor也负责预测gt bbox
- 遍历每个负anchor的预测值,如果anchor预测值和其余所有gt bbox的所有iou值中(不需要网格限制),只要有一个iou值大于阈值,则该anchor预测值忽略,不计算loss
bbox编解码
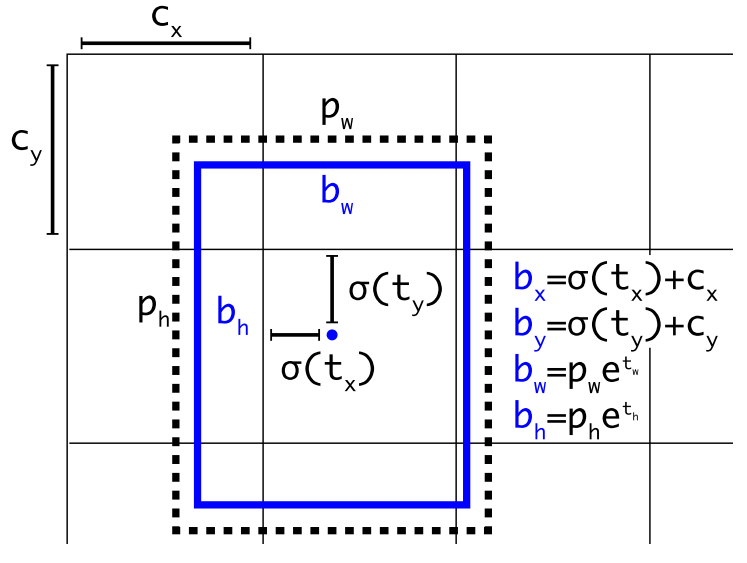
yolov2的bbox编解码结合了yolov1和ssd的做法,具体是:对于xy中心点值的预测不变,依然是预测相对当前网格左上角偏移。但是对于wh的预测就不同了,主要原因是有anchor了,其wh预测值是gt bbox的宽高除以anchor的wh,然后取log操作即可(和ssd的bbox编解码是一样的),并且gt box和anchor尺度都会先映射到特征图上面再计算。可以发现xy的预测范围是0~1,但是wh的预测范围不定。
确定了编码过程,那么解码过程也非常简单,就是上面图中的公式,cx,cy的范围是0~13,因为xy预测范围是0~1,故对预测的tx,ty会先进行sigmoid操作(yolov1没有进行sigmoid),然后加上当前网格左上角坐标,最后乘上stride即可得到bbox的中心坐标,而wh就是预测值tw,th进行指数映射然后乘上特征图尺度的anchor宽高值,最后也是乘上stride即可。
相比于yolov1的编解码方式,采用anchor有诸多好处,最主要是可以克服yolov1早期训练极其不稳定问题,原因是其在早期训练时候每个网格都会输出B个任意形状的预测框,这种任意输出可能对某些特定大小的物体有好处,但是会阻碍其他物体学习,导致梯度出现瞬变,不利于收敛。而通过引入基于统计物体wh分布的先验anchor,相当于限制了回归范围,训练自由度减少了,自然收敛更加容易,训练更加稳定了。
loss设计

和yolov1一样,所有分支loss都是l2 loss,同时为了平衡正负样本,其也有设置不同分支的loss权重值。
(1) bbox回归分支loss
首先$1k^{truth}$的含义是所有正样本为1,否则是0,也就是说bbox回归分支仅仅计算正样本loss。$truth^r$是gt bbox的编码target值,$b^r$是回归分支预测值tx,ty,tw,th,对这4个值计算l2 loss即可。
1t < 128000是指前128000次迭代时候额外考虑一个回归loss,其中$prior^r$表示anchor,表示预测框与先验框anchor的误差,注意不是与gt bbox的误差,可能是为了在训练早期使模型更快学会先预测先验框的位置。 这个loss的目的是希望忽略xy的学习,而侧重于将预测wh学习出anchor的形状,可能有助于后面的收敛。
(2) 分类回归loss 分类分支预测值是$b^c ,truth^c$表示对应的one-hot类别编码,该分支也仅仅是计算正样本anchor。
(3) 置信度分支loss 对于置信度分支loss计算和yolov1里面完全相同,对于正样本其label是该anchor预测框结果解码后还原得到预测bbox,然后和gt bbox计算iou,该iou值作为label,用于表示有没有物体且当有物体时候预测bbox的准确性,对于负样本其label=0。上图中$1_{maxIOU}<Thresh$的其实就是表示负样本,可以看出忽略样本全程都是不参与loss计算的。
推理流程
对于每个预测框,首先根据类别置信度确定其类别与分类预测分值,将类别概率和confidence值相乘。然后根据阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框,最后剩余的预测框就是检测结果了。
总结
通过分析yolov1的召回率低、定位精度差的缺点,并且结合ssd的anchor策略,提出了新的yolov2算法,在BN、新网络darknet19、kmean自动anchor聚类、全新bbox编解码、高分辨率分类器微调、多尺度训练和passthrough的共同作用下,将yolov1算法性能进行了大幅提升,同时保持了yolov1的高速性能。
YOLOv3
YOLOv3总体思想和YOLOv2没有任何区别,只不过引入了最新提升性能的组件。
主要贡献:基于retinanet算法引入了FPN和多尺度预测;基于主流resnet残差设计思想提出了新的骨架网络darknet53 ;不再将所有loss都认为是回归问题,而是分为分类和回归loss,更加符合主流设计思想。
网络结构
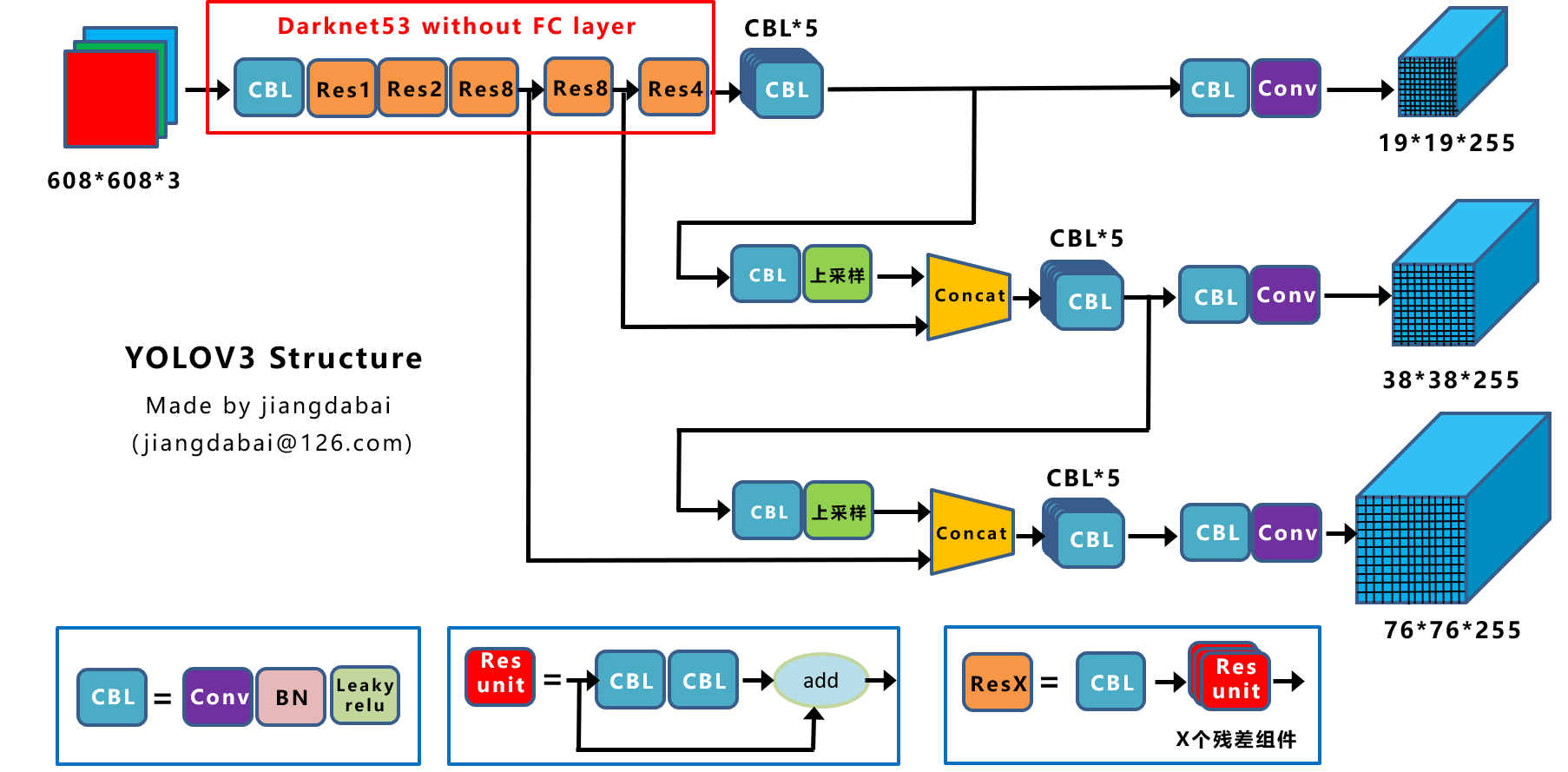
Yolov3的三个基本组件:
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
- Concat:张量拼接,会扩充两个张量的维度,例如26x26x256和26x26x512两个张量拼接,结果是26x26x768。Concat和cfg文件中的route功能一样。
- add:张量相加,张量直接相加,不会扩充维度,例如104x104x128和104x104x128相加,结果还是104x104x128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
正负样本定义
规则和yolov2完全相同,只不过任何一个gt bbox和anchor计算iou的时候是会考虑三个预测层的anchor,而不是将gt bbox和每个预测层单独匹配。假设某个gt bbox和第二个输出层的某个anchor是最大iou,那么就仅仅该anchor负责对应gt bbox,其余所有anchor都是负样本。同样的yolov3也需要基于预测值计算忽略样本。
从yolov2的单尺度预测变成了yolov3多尺度预测,其匹配规则为:
- 遍历每个gt bbox,首先判断其中心点落在哪3个网格(三个输出层上都存在),然后和那3个网格内的所有anchor(一共9个anchor)计算iou,iou最大的anchor就负责匹配即正样本,其余8个anchor都暂时是负样本。可以看出其不允许gt bbox在多个输出层上都预测
- 考虑额外规则:当每个gt bbox和最大iou的anchor匹配完成后,对剩下的anchor再次和对应网格内的gt bbox进行匹配(必须限制在对应网格内,否则xy预测范围变了),当该anchor和gt bbox的iou大于一定阈值例如0.7后,也算作正样本,即该anchor也负责预测gt bbox
- 遍历每个负anchor的预测值,如果anchor预测值和其余所有gt bbox的所有iou值中(不需要网格限制),只要有一个iou值大于阈值,则该anchor预测值忽略,不计算loss
bbox编解码
规则和yolov2完全相同,正样本的xy预测值是相对当前网格左上角的偏移,而wh预测值是gt bbox的wh除以anchor的wh(注意wh是在特征图尺度算还是原图尺度算是一样的,解码还原时候注意下就行),然后取log得到。
loss设计
和YOLOv2不同的是,对于分类和置信度预测值,其采用的不是l2 loss,而是bce loss,而回归分支依然是l2 loss。
分类问题一般都是用ce或者bce loss,而在retinanet里面提到采用bce loss进行多分类可以避免类间竞争,对于coco这种数据集是很有好处的;其次在机器学习中知道对于逻辑回归问题采用bce loss是一个凸优化问题,理论上优化速度比l2 loss快;而且分类输出就是一个概率分布,采用分类常用loss是最常规做法,没必要统一成回归问题。
推理流程
- 遍历每个输出层,对xy预测值采用sigmoid变成0~1,然后进行解码,具体是对遍历每个网格,xy预测值加上当前网格坐标,然后乘上stride即可得到预测bbox中心坐标,对于wh预测值先进行指数计算,然后直接乘上anchor的wh即可,此时就可以还原得到最终的bbox
- 对置信度分支采用sigmoid变成0~1,分类分支由于是bce loss故也需要采用sigmoid操作
- 利用置信度预测将置信度值低于预测的预测值过滤掉
- 如果剩下的预测bbox数目多于设置的nms前阈值个数1000,则直接对置信度值进行从大到小topk排序,提取前1000个,三个输出层最多构成3000个预测bbox
- 对所有预测框进行nms即可
总结
yolov3可以认为是当前目标检测算法思想的集大成者,其通过引入主流的残差设计、FPN和多尺度预测,将one-stage目标检测算法推到了一个速度和精度平衡的新高度。由于其高速高精度的特性,在实际应用中通常都是首选算法。
YOLOv4
YOLOv4算是当前各种trick的集大成者,尝试了许多提升性能的组件。
网络结构
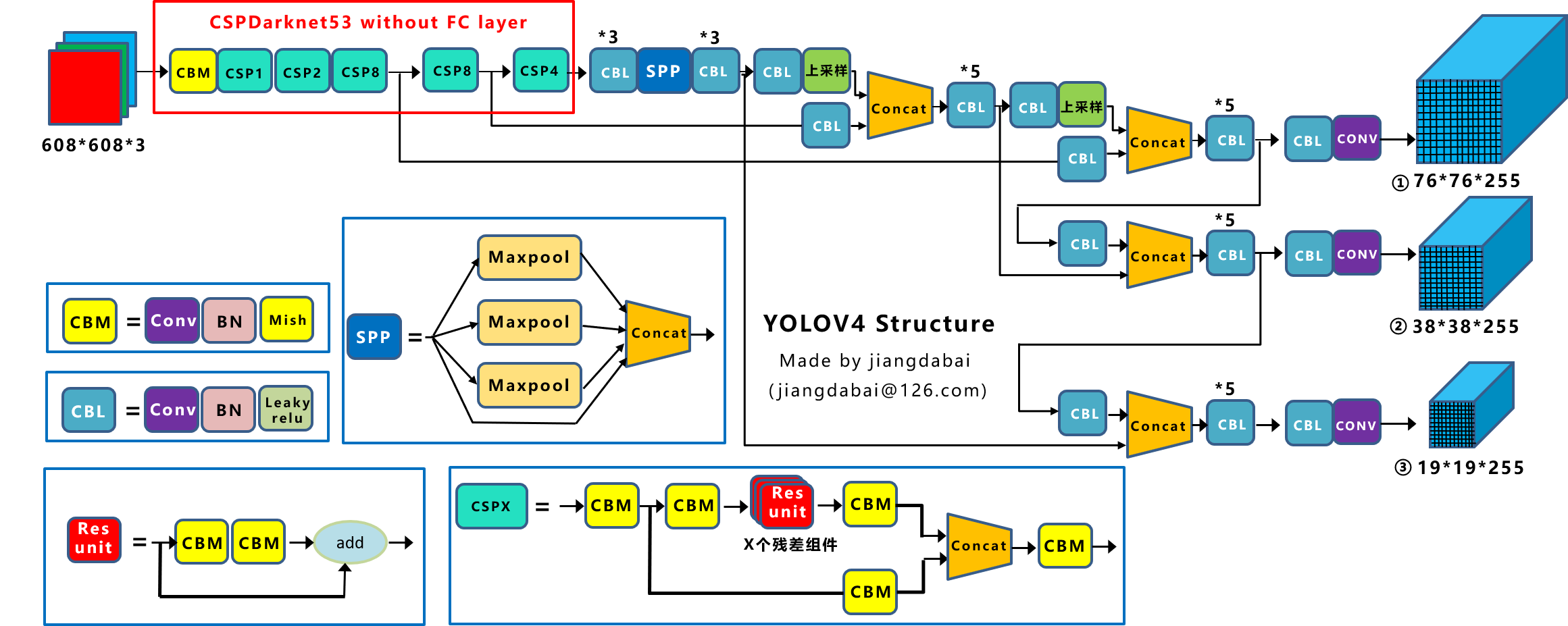
YOLOv4的五个基本组件:
- CBM:YOLOv4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
- Concat:张量拼接,维度会扩充,和YOLOv3中的解释一样,对应于cfg文件中的route操作。
- add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。
Backbone中卷积层的数量:
和YOLOv3一样,再来数一下Backbone里面的卷积层数量。
每个CSPX中包含5+2xX个卷积层,因此整个主干网络Backbone中一共包含1+(5+2x1)+(5+2x2)+(5+2x8)+(5+2x8)+(5+2*4)=72。
YoloV4的创新之处:
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如YOLOv4中的SPP模块、FPN+PAN结构
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
YOLOv5
网络结构
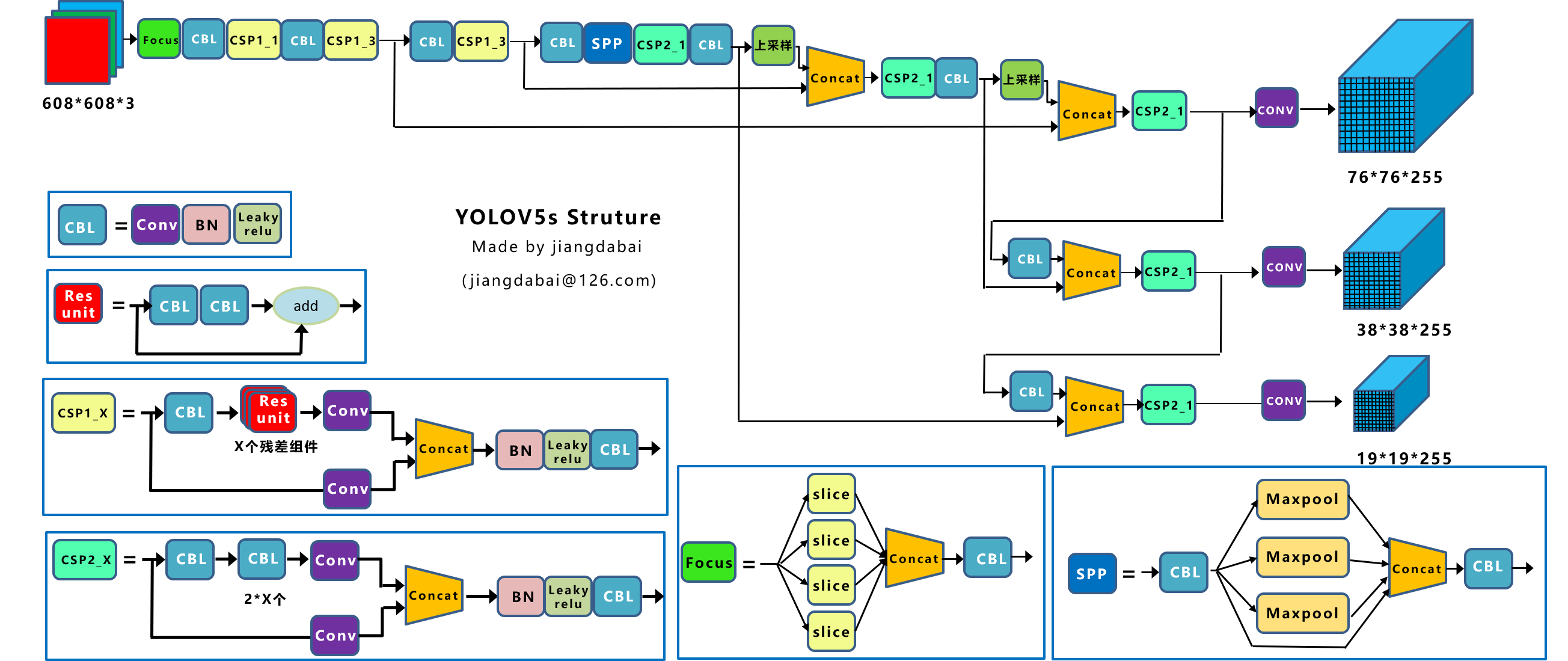
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放 (2)Backbone:Focus结构,CSP结构应用于Neck中 (3)Neck:FPN+PAN结构 (4)Prediction:GIOU_Loss
正负样本定义
yolov5匹配规则为:
(1) 对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景 。 (2) 对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前YOLO系列,至少增加了三倍。
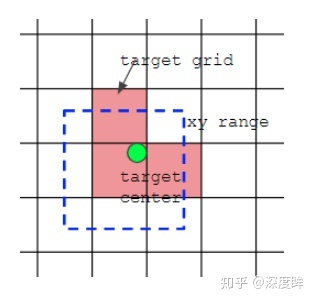
bbox编解码说明
Yolov3边框预测
$C_x、C_y$是feature map中grid cell的左上角坐标,每个grid cell在feature map中的宽和高均为1。图中的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故$C_x=1,C_y=1$。公式中$P_w、P_h$为预设的anchor box映射到feature map中的宽和高(anchor box原本设定是相对于416*416坐标系下的坐标,除以stride如32映射到feature map坐标系中)。得到边框坐标值是$b_x,b_y,b_w,b_h$即边界框bbox相对于feature map的位置和大小。但网络实际上的学习目标是$t_x,t_y,t_w,t_h$这4个offsets,其中$t_x,t_y$是预测的坐标相对于$C_x、C_y$的偏移值,$t_w,t_h$是相对于$P_w、P_h$的尺度缩放,有了这4个offsets,自然可以根据之前的公式去求得真正需要的$b_x,b_y,b_w,b_h$4个坐标。通过学习偏移量,就可以通过网络原始给定的anchor box坐标经过线性回归微调(平移加尺度缩放)去逐渐靠近groundtruth。
这里需要注意的是,虽然输入尺寸是416x416,但原图是按照纵横比例缩放至416x416的, 取 min(w/img_w, h/img_h)这个比例来缩放,保证长的边缩放为需要的输入尺寸416,而短边按比例缩放不会扭曲,img_w,img_h是原图尺寸768,576, 缩放后的尺寸为new_w, new_h=416,312,需要的输入尺寸是w,h=416,416。剩下的灰色区域用(128,128,128)填充即可构造为416x416。不管训练还是测试时都需要这样操作原图。而且我们注意yolov3需要的训练数据的label是根据原图尺寸归一化了的,这样做是因为怕大的边框的影响比小的边框影响大,因此做了归一化的操作,这样大的和小的边框都会被同等看待了,而且训练也容易收敛。既然label是根据原图的尺寸归一化了的,自己制作数据集时也需要归一化才行。

这里解释一下anchor box,YOLOv3为每种FPN预测特征图(13x13,26x26,52x52)设定3种anchor box,总共聚类出9种尺寸的anchor box。在COCO数据集这9个anchor box是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。分配上,在最小的13x13特征图上由于其感受野最大故应用最大的anchor box (116x90),(156x198),(373x326),(这几个坐标是针对416x416下的,当然要除以32把尺度缩放到13x13),适合检测较大的目标。中等的26x26特征图上由于其具有中等感受野故应用中等的anchor box (30x61),(62x45),(59x119),适合检测中等大小的目标。较大的52x52特征图上由于其具有较小的感受野故应用最小的anchor box(10x13),(16x30),(33x23),适合检测较小的目标。特征图的每个像素(即每个grid)都会有对应的三个anchor box,如13x13特征图的每个grid都有三个anchor box (116x90),(156x198),(373x326)(这几个坐标需除以32缩放尺寸)。
那么4个坐标$t_x,t_y,t_w,t_h$是怎么求出来的呢?
$C_x,C_y,P_w,P_h$是预设的anchor box在feature map上目标中心点grid cell位置和宽高。
$G_x,G_y,G_w,G_h$是ground truth除以stride映射到feature map的4个坐标。
YOLOv3里是$G_x,G_y$减去grid cell左上角坐标$C_x,C_y$,为需要预测的偏移。
\(t_x=G_x-C_x\\ t_y=G_y-C_y\\ t_w=log(G_w/P_w)\\ t_h=log(G_h/P_h)\\\) \(b_x=\sigma(t_x)+C_x\\ b_y=\sigma(t_y)+C_y\\ b_w=P_we^{t_w}\\ b_h=P_he^{t_h}\\\)
不直接回归bounding box的长宽而是尺度缩放到对数空间,是怕训练会带来不稳定的梯度。因为如果不做变换,直接预测相对形变$t_w,t_h$,那么要求$t_w,t_h>0$,因为框的宽高不可能是负数。这样,是在做一个有不等式条件约束的优化问题,没法直接用SGD来做。所以先取一个对数变换,将其不等式约束去掉。
边框回归最简单的想法就是通过平移加尺度缩放进行微调。边框回归为何只能微调?当输入的 Proposal 与 Ground Truth 相差较小时,即IOU很大时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归(线性回归就是给定输入的特征向量 X, 学习一组参数 W, 使得经过线性回归后的值跟真实值 Y(Ground Truth)非常接近. 即Y≈WX )来建模对窗口进行微调, 否则会导致训练的回归模型不work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然就不合理了)。
Yolov5边框预测
yolov5为了增加正样本数量增加了最近两个网格进行预测,编码解码略有不同
\[b_x=\sigma(t_x)*2-0.5+C_x\\ b_y=\sigma(t_y)*2-0.5+C_y\\ b_w=P_w*(t_w*2)^2\\ b_h=P_h*(t_h*2)^2\\\]
-
SSD
SSD
论文:SSD-Single Shot MultiBox Detector
主要贡献
除了YOLO系列,SSD也算是one-stage目标检测算法的先行者了,相比于YOLOV1和FasterRCNN,其主要特点是:
(1) 在one-stage算法中引入了多尺度预测(主要是为了克服CNN不具有尺度不变性问题)
(2) 参考FasterRCNN中anchor的概念,将其引入one-stage中,通过在每个特征图位置设置不同个数、不同大小和不同比例的anchor box来实现快速收敛和优异性能
(3) 采用了大量有效的数据增强操作
(4) 从当时角度来看,速度和性能都超越当时流行的YOLOV1和FasterRCNN
即使到目前为止,多尺度预测加上anchor辅助思想依然是主流做法。
网络结构
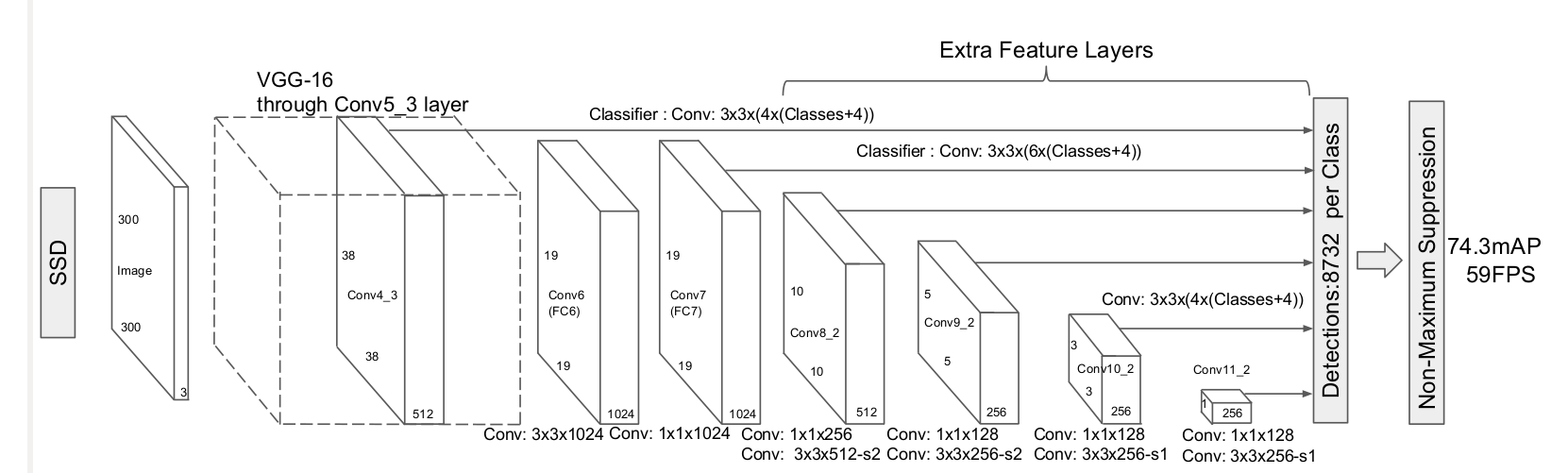
主要 (1)多尺度预测; (2)引入了anchor;(3) 全卷积形式,按照目标检测通用算法流程思路来讲解。ssd也是包括backbone、head、正负样本定义、bbox编解码和loss设计5个部分。
backbone
SSD的骨架是VGG16,其是当前主流的分类网络,其主要特点是全部采用3x3的卷积核,然后通过多个卷积层和最大池化层堆叠而成,是典型的直筒结构。
假设是SSD300,那么一共包括6个输出特征图,分别命名为conv4_3、conv7、conv8_2、conv9_2、conv10_2和conv11_2,其wh大小分别是38x38、19x19、10x10、5x5、3x3和1x1,而SSD512包括7个输出特征图,命名论文中没有给出,其wh大小分别是64x64、32x32、16x16、8x8、4x4、2x2、1x1。
需要注意的是:作者实验发现,conv4_3层特征图比较靠前,其L2范数值(平方然后开根号)相比其余输出特征图层比较大,也就是数值不平衡,为了更好收敛,作者对conv4_3+relu后的输出特征图进行l2 norm到设置的初始20范围内操作,并且将20这个数作为初始值,然后设置为可学习参数。
head
backbone模块会输出n个不同尺度的特征图,head模块对每个特征图进行处理,输出两条分支:分类和回归分支。假设某一层的anchor个数是m,那么其分类分支输出shape=(b,(num_cls+1)×m,h’,w’),回归分支输出shape=(b,4*m,h’,w’)。
正负样本定义
在说明正负样本定义前,由于SSD也是基于anchor变换回归的,而且其有一套自己根据经验设定的anchor生成规则,故需要先说明anchor生成过程。
就是对输出特征图上面任何一点,都铺设指定数目,但是不同大小、比例的先验框anchor。
对于任何一个尺度的预测分支,理论上anchor设置的越多,召回率越高,但是速度越慢。为了速度和精度的平衡,作者在不同层设置了不同大小、不同个数、不同比例的anchor,下面进行详细分析。
以SSD300为例,其提出了一个公式进行设计:
\[s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1),k\in[1,m]\]公式的含义是:输出特征图从大到小,其anchor尺寸设定遵循线性递增规则:随着特征图大小降低,先验框尺度线性增加,从而实现大特征图检测小物体,小特征图检测大物体效果。这里的m是值特征图个数,例如ssd300为6,ssd512为7。第一层conv43是单独设置,不采用上述公式,$s_k$表示先验框大小相对于图片的base比例,而$s{min}$、$s_{max}$表示比例的最小和最大值,voc数据集默认是0.2和0.9,coco数据集默认是0.15和0.9。
(1) 先算出每个输出特征图上anchor的最大和最小尺度 第一个输出层单独设置,其min_size=300x10/100=30,max_size=300x20/100=60。 从第二个输出层开始,首先将乘上100并且取整,得到min_ratio和max_ratio,然后计算出step步长为:
int(np.floor(max_ratio - min_ratio) / (num_levels=6 - 2))最后利用step计算得到每个输出层的min_size和max_size
# 计算第2个输出图和第self.num_levels个特征图anchor的min_size和max_size for ratio in range(int(min_ratio), int(max_ratio) + 1, step): min_sizes.append(int(300 * ratio / 100)) max_sizes.append(int(300 * (ratio + step) / 100)) # 第1个输出图单独算min_size和max_size if self.input_size == 300: # conv4_3层的anchor单独设置,不采用公式 if basesize_ratio_range[0] == 0.15: # SSD300 COCO min_sizes.insert(0, int(300 * 7 / 100)) max_sizes.insert(0, int(300 * 15 / 100)) elif basesize_ratio_range[0] == 0.2: # SSD300 VOC min_sizes.insert(0, int(300 * 10 / 100)) max_sizes.insert(0, int(300 * 20 / 100))这样就可以得到6个输出图所需要的min_size和min_size数值,注意这是原图尺度。
(2) 计算(0,0)特征图坐标处的anchor尺度和高宽比 首先配置参数为ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),如果某一层的比例是2,那么表示实际高宽比例是[1,1/2,2],如果是3,则表示[1,1/3,3],可以看出如果某一层ratio设置为[2,3],那么实际上比例有[1,2,3,1/2,1/3]共5种比例,而尺度固定为[1., np.sqrt(max_sizes[k] / min_sizes[k])],k为对应的输出层索引。
带目前为止,6个特征图对应的anchor个数为[2x3=6,2x5=10,10,10,6,6],表示各种比例和尺度的乘积。
(3) 利用base值、anchor尺度和高宽比计算得到每层特征图上(0,0)位置的实际anchor值 这个计算就和常规的faster rcnn完全相同了,计算(0,0)点处的实际宽高,然后利用中心偏移值得到所有anchor的xyxy坐标。
(4) 对特征图所有位置计算anchor 直接将特征图上坐标点的每个位置都设置一份和(0,0)坐标除了中心坐标不同其余都相同的anchor即可,也就是将(0,0)特征图位置上面的anchor推广到所有位置坐标上。基于前面的分析,SSD300一共有8732个anchor。
匹配规则如下:
- 对每个gt bbox进行遍历,然后和所有anchor(包括所有输出层)计算iou,找出最大iou对应的anchor,那么该anchor就负责该gt bbox即该anchor是正样本,该策略保证每个gt bbox一定有一个anchor进行匹配
- 对每个anchor进行遍历,然后和所有gt bbox计算iou,找出最大iou值对应的gt bbox,如果最大iou大于正样本阈值0.5,那么该anchor也负责对应的gt bbox,该anchor为正样本。该策略可以为每个gt bbox提供尽可能多的正样本
- 其余没有匹配上的anchor全部是负样本。
bbox编解码
对于任何一个正样本anchor位置,其gt bbox编码方式采用的依然是Faster rcnn里面的变换规则DeltaXYWHBBoxCoder即
-
目标检测问题
目标检测问题
建模方式
分治(multi-region classification & regression)
一张图上预定义若干regions,然后对每个region逐一进行分类与回归
这个region附近是否存在物体,如果存在,那么这一物体是什么类别,而它的位置相对于这个region又在哪里
需要解决的问题
这种建模方式需要解决哪些问题?
问题1:怎样设计“region”
这个“region”的设计更多的反映的是对于所需要解决的问题及场景的先验。
在RetinaNet等anchor-based的算法中,它的名字叫做anchor;在FCOS等anchor-free的算法中,它又代表着anchor point;
问题2:每个“region”负责多大的范围
概括为anchor design & label assignment问题
RetinaNet在图片上均匀平铺了一系列不同尺度、不同长宽比的region(anchor),并基于gt bbox和anchor的IoU,定义了“管辖范围”;而FCOS等anchor-free算法中则平铺了一系列anchor point,并采用中心点距离+尺度约束的方式定义了“管辖范围”;ATSS中提出设置自适应的阈值,来定义“管辖范围”;当然上述方案都是静态的设定了“管辖范围”,近年出现了另一类改进方案,诸如FreeAnchor,AutoAssign,PAA等算法中则提出了动态的 “管辖范围”设置方案(即“管辖范围”与网络的输出相关);
对于anchor design & label assignment的问题,如果想要得到更理想的检测算法性能,需要研究dense和multi-stage refine之间的折中,有些致力于解决极端正负样本不平衡问题以使得dense anchor发挥出更大的作用,例如RetinaNet (Focal loss);有些则设计各种多级refine的方案,例如Faster RCNN,Cascade RCNN, RefineDet,RPDet,AlignDet,Guided anchoring,Cascade RPN等;有些则尝试提出更有效的region & label assignment方案,例如FCOS,CenterNet,ATSS,FreeAnchor等。
问题3:怎样有效提取每个“region”的特征做分类和回归
首先,我们可以考虑多个区域共享由全图提取的特征,而无需逐区域计算特征(Fast R-CNN中提出);其次,CNN可以提取“规范”区域的特征,即落在grid上、长宽比一定的区域的特征;而对于“非规范”区域,可以通过池化/插值的形式得到这些区域的特征(ROI pooling/ROI Align/Deformable Conv w. specified offsets等)。从这个角度说,如果把anchor理解为original proposal,那么faster r-cnn等一系列multi-stage detector中rpn和r-cnn所做的事情并没有本质差别。
目标检测网络
可以从以下6部分分析一个目标检测网络
- 网络backbone设计
- 网络neck设计
- 网络head设计
- 正负样本定义
- bbox编解码设计
- loss设计
-
分类问题
CNN:我不是你想的那样
论文名称:High-frequency Component Helps Explain the Generalization of Convolutional Neural Networks
github:https://github.com/HaohanWang/HFC
每当我们训练完一个CNN模型进行推理时候,一旦出现人类无法解释的现象就立刻指责CNN垃圾,说这都学不会?其实你可能冤枉它了,而本文试图为它进行辩护。
本文是cvpr2020 oral论文,核心是从数据高低频分布上探讨CNN泛化能力,其注意到CNN具备捕获人类无法感知的高频成分能力,而这个现象可以用于解释多种人类无法理解的假设,例如泛化能力、对抗样本鲁棒性等。
本文其实没有提出一个具体的解决办法,主要是通过CNN能够捕获人类无法感知的高频成分这一现象而对所提假设进行分析。我个人觉得本文应该作为cv领域从业者的必读论文。
论文思想
图片高低频分离(非重点)
为了方便后面分析,先对图片的高低频分离过程进行说明(如果看不懂也无所谓,不影响阅读,知道啥是高低频成分就可以了)。
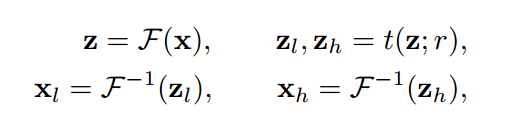 表示样本对,x是图片,y是对应的标注,表示傅里叶变换,表示反傅里叶变换,表示对样本x进行傅里叶变换,z是x的频率分量,表示反傅里叶变换。而表示阈值函数,该函数通过一个半径阈值,将频率分量分成低频分量和高频分量,该阈值函数具体如下:
表示样本对,x是图片,y是对应的标注,表示傅里叶变换,表示反傅里叶变换,表示对样本x进行傅里叶变换,z是x的频率分量,表示反傅里叶变换。而表示阈值函数,该函数通过一个半径阈值,将频率分量分成低频分量和高频分量,该阈值函数具体如下:
其中表示当前位置和中心位置之间的距离,文中用的是欧氏距离。注意在FFT频谱图中靠近中心区域是低频分量,远离中心区域是高频分量。低频成分一般就是图片纹理或者信息,高频成分就是一些边缘和像素锐变区域。
简单来说就是对一张32x32的图片进行FFT变换,输出也是32x32频谱图,其中越靠近中心越是低频成分,然后在FFP频谱图中心设置一个半径为r的圆,圆内频谱成分保留,其余成分置为0,通过逆傅里叶变换得到重建图片,该图片即为保留低频成分后的像素图。r越大,圆内保留的成分越多,信息丢失越少,重建后原图信息越多。当r比较小的时候大部分高频成分会被抛弃,重建图会非常模糊。
初步实验分析
为了引入本文论点,作者做了一个简单实验。首先用CIFAR10在训练数据训练一个resnet18分类模型,接着在测试集上进行测试,此时可以得到模型正确率,接着进一步通过傅里叶变换,把原图转换到频域,再用一个半径阈值r=12,分离出高频部分和低频部分,再对高频和低频部分进行反傅里叶变换,得到高频重建图片和低频重建图片,然后测试这两张图片。结果出现了一些非常奇怪的现象:模型对人眼看上去和原图差不多的低频图错误预测,反而正确预测了全黑的高频图。一个典型图片如下所示:
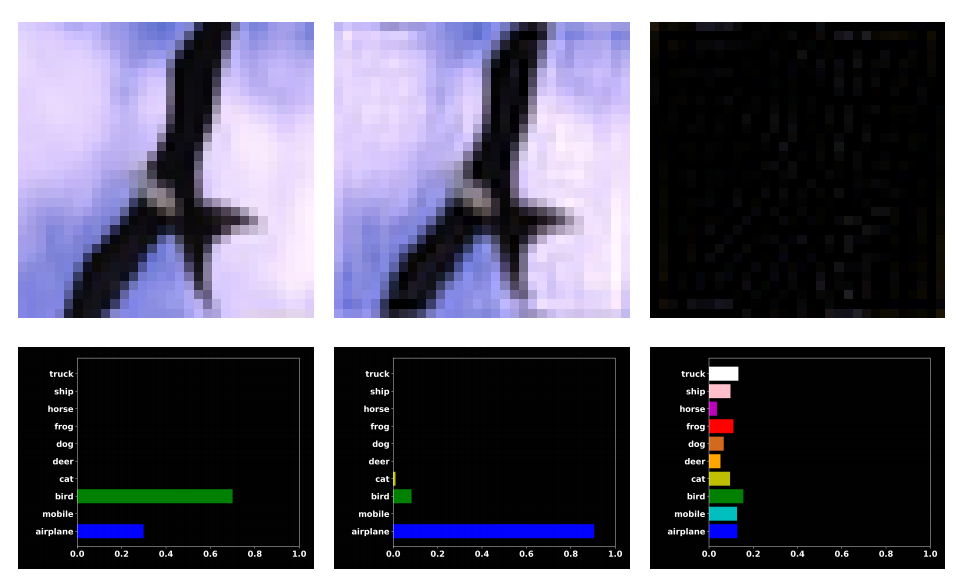
左边图是原始测试图,可以看出其很大概率认为是鸟,但是对低频成分重建图(中间图)却几乎可以肯定是飞机,高频成分重建图(右边图)到是预测为鸟,这种现象在10k张测试集中大概有600张。
这种现象完全不符合人类的认知。
提出假设
针对上述不符合常理的现象,作者提出了合理假设:人类只能感知低频分量,而CNN对低频和高频分量都可以感知,图示如下:
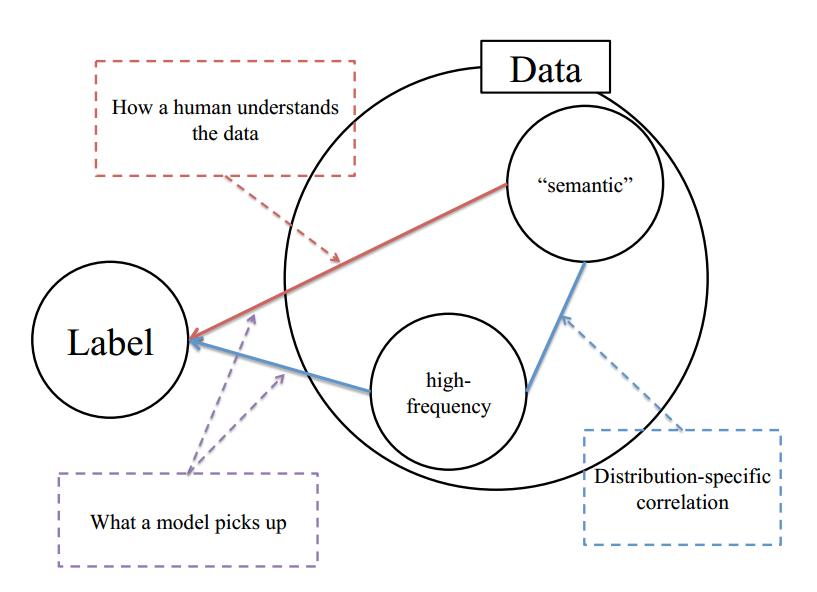
对于任何一个数据集,都应该包括语义信息(纹理信息或者说低频信息)和高频信息,只不过包括比例不定而已,并且对于同一个分布数据集,其语义分布和高频分布都应该有自己的分布特性。可以简单认为对于同一个类别标注的数据集,假设该数据集收集自多个场景,每个场景内的语义分布应该是近乎一致的(不然也不会标注为同一类),但是高频分布就不一定了,可能和特定域有关,该高频成分可能包括和类别相关的特定信息,也可以包括分布外的噪声,并且该噪声对模型训练是有害的,会影响泛化能力。
对于人类而言,标注时候由于无法感知高频成分故仅仅依靠语义进行标注,忽略了高频成分。但是CNN训练时候会同时面对语义低频成分和高频成分,这个gap就会导致CNN学习出来的模型和人类理解的模型不一样,从而出现常规的泛化认知错误。这一切实际上不能怪CNN,而是数据分布特性决定的。
当CNN采用优化器来降低损失函数时,人类并没有明确告知模型去学习语义还是高频信号,这导致模型学习过程中可能会利用各种信息来降低损失。这样尽管模型可能会达到较高的准确率,但它理解数据的过程和人类不一样,从而导致大家认为CNN很垃圾。
而且论文中未避免被后续论文打脸,还特意指出:本文并没有说模型有捕捉高频信号的倾向性,这里的主要观点是模型并没有任何理由忽略高频信息,从而导致模型学到了高频和语义的混合信息。
实验论证假设
上述假设是作者自己提出的,为了使得假设更加可信,作者进行了后续详细实验。
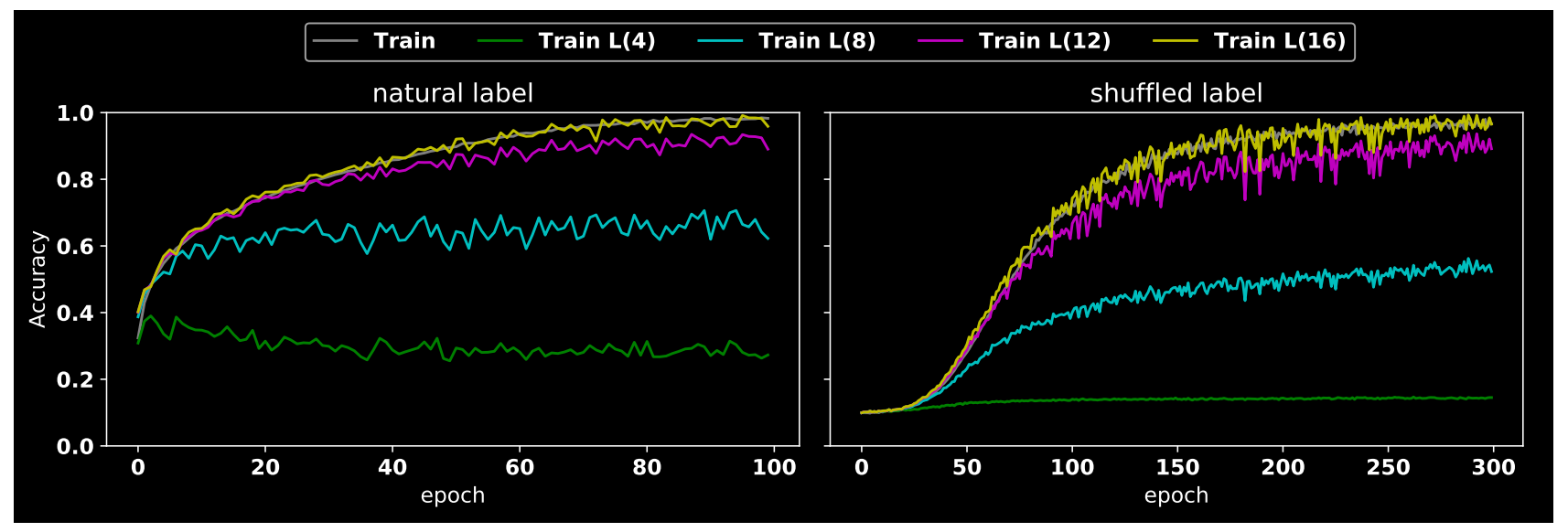
(1) nutural label VS shuffled label nutural label就是原始标注label即原始图片和label对,而shuffled label是对label随机打乱导致有些label错误的情形。将这两种数据分别在cifar10训练集上采用resnet18进行训练,训练过程acc曲线如上所示,其中L(n)表示对图片采用半径为n的阈值过滤掉高频成分,然后对保留频谱成分进行重建,注意n越大,保留的信息更多。
从图中可以看出很多重要信息,其现象具体如下:
- 从shuffled label的黄线可以看出,即使把label随机打乱,也可以得到非常高的准确率,只不过需要更多的epoch,而且震荡也比较厉害。这个现象其实在Understanding deep learning requires rethinking generalization论文中有做过相关工作
- 当半径n由小变大时候,不管是shuffled label还是natural label,acc都是从低变高
- 刚开始训练时候natural label的acc起点比shuffled label高40%
下面对上述现象进行分析:
- CNN的记忆能力很强,即使label随机打乱,acc也可以接近1。我们通常认为cnn强拟合能力把label直接记住了,但是这就出现一个问题了:既然natural label能够轻易的就记住所有label,那为何还CNN训练过程中还会考虑测试集的泛化能力呢?因为在Understanding deep learning requires rethinking generalization中提到虽然cnn可以强行记住label,但是有些模型还是有较好泛化能力的,这就解释不通了
- 上述现象如果从数据高低频角度考虑就可以解释通。因为刚开始训练时候natural label的acc起点比shuffled label高40%,所以我们可以推导:cnn在训练早期会先利用语义信息或者说低频信息进行训练,当loss不能再下降时候会额外引入高频成分进一步降低loss。因为shuffled数据集的label被随机打乱了,所以cnn无法利用语义低频信息进行训练,但是在后期开始引入高频成分从而acc最终变成1,而natural label由于有低频语义信息,故刚开始很快acc就变成40%,后面也开始引入高频信息进一步提高acc。
- 当半径n由小变大时候,不管是shuffled label还是natural label,acc都是从低变高现象出现的原因也是上述道理,因为随着r变大,高频成分保留的越来越多,cnn后期能利用的高频成分越来越多,所以loss可以不断下降
总结下:cnn训练过程会先采用低频语义信息进行降低loss,当继续训练无法降低loss时候会额外考虑高频成分进一步降低loss,而由于label被shuffle掉导致无法利用低频语义信息,则出现刚开始acc为0的现象,但是因为后期利用了高频成分,故最终还是能够完全拟合数据。
需要特别强调的是:高频成分可以分成两部分:和数据分布相关的有用高频成分A、和数据无关的噪声有害高频成分B。在natural label数据训练过程中,cnn可能会利用AB两种高频成分进行过拟合,而且由于利用的AB比例无法确定,故而就会出现CNN模型存在不同的泛化能力,如果噪声成分引入的多,那么对应的泛化能力就下降。
通过上述现象,我们很容易解释早停止手段为何可以防止过拟合,因为越到训练后期其可利用的和数据相关的有用高频成分就越少,为了降低loss,就只能进一步挖掘样本级别的特有的噪声高斯信息。
遗憾的是暂时没有一种手段把噪声高频成分过滤掉,仅仅保留有用高频成分。
(2) 低频成分 VS 高频成分
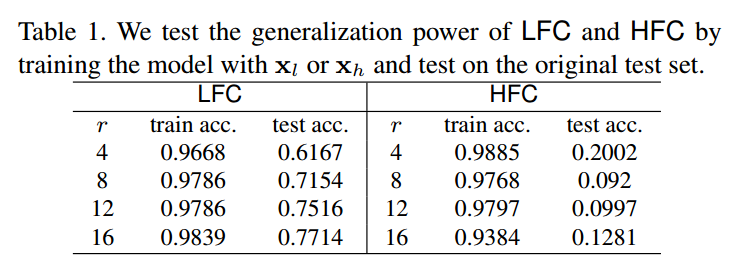
对图片进行高低频分离然后重建,得到图片,在这两种数据上训练,然后在原始数据集上测试,结果如上所示。可以得到如下结论:
- 随着r变大,由于保留的高频成分越多,所以训练集和测试集准确率都增加了,这其实说明高频成分不全是噪声,很多应该还是和数据分布相关的有用信息
- 采用低频成分训练的泛化能力远远高于高频成分训练的模型。这个现象造成的原因是label是人类标注的,人类本身就是按照低频语义信息进行标注,可以大胆猜测,如果人类能够仅仅利用高频成分进行标注,那么上述现象应该就是相反的
(3) 启发式组件通俗解释 这里说的启发式组件是指的Dropout、Mix-up、BatchNorm和Adversarial Training等,这些组件已经被证明可以提高模型泛化能力,作者试图采用本文观点进行分析成功的原因。
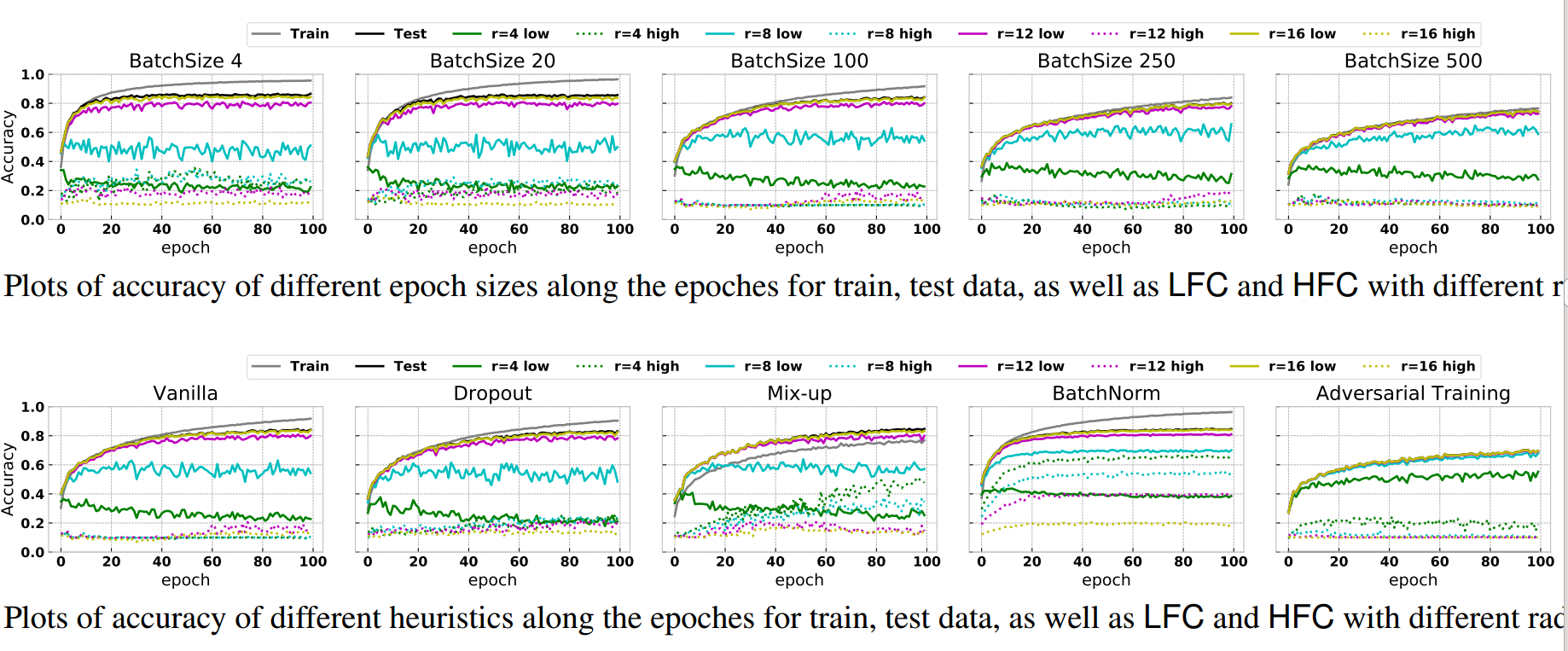
上图比较多,主要看第二行,但是可以归纳为:
- 大batch size训练时候,会同时考虑更多的非噪声的同分布高频成分,从而可以缩小训练和测试acc的误差间隔
- dropout由于加入后和不加入时候差不多,所以看不出啥规律
- 加入mixup后,训练acc和测试acc曲线gap变小,原因是mixup操作其实相当于混淆了低频语义信息,从而鼓励CNN尽可能多的去捕获高频信息
- 当引入对抗样本后,cnn精度快速下降,原因是对抗样本可能是改变了高频分布(因为人眼无法感知),而训练过程中实际上学到的高频分布和对抗样本的高频分布不一致,从而CNN会完全预测错误
- BN的分析作者单独进行分析
从以上分析可以看出,如果试图从数据的高低频分布以及CNN先学低频再学高频这个特性进行分析目前所提组件,是完全可以解释通的。
(4) BN训练过程分析
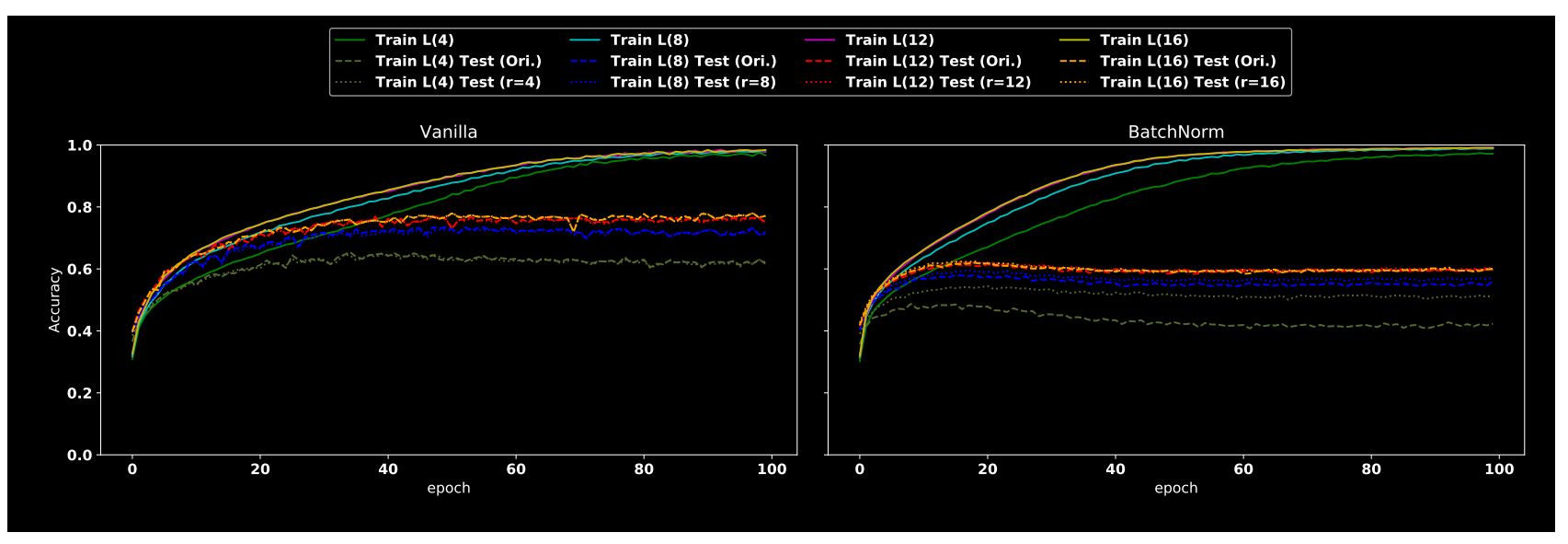
vaillla是指没有引入BN的模型。作者假设BN优势之一是通过归一化来对齐不同预测信号的分布差异,没有经过BN训练的模型可能无法轻松获取这些高频成分,而且高频成分通常是较小的幅度,通过归一化后可以增加其幅值。总之BN层引入可以让模型轻易捕获高频成分,并且由于对齐效应,大部分捕获的会是有用高频成分,从而加快收敛速度,提高泛化能力。
对抗攻击和防御
前面分析了特别多,但是除了加深对CNN的理解外,好像没有其他作用。为了消除大家对本文贡献的错觉,作者说可以将上述思想应用到对抗攻击和防御领域,加强模型鲁棒性。
前面说过对抗样本可以和高频成分联系起来,其可以认为是扰动了人类无法感知的高频成分,从而使得网络无法识别。作者首先分析对抗样本对网络造成的影响,然后提出了针对性改进。
首先采用标准的FGSM或者PGD等方法生成对抗样本,然后将对抗样本联合原始数据进行训练,最后可视化第一次卷积核参数,如下所示:
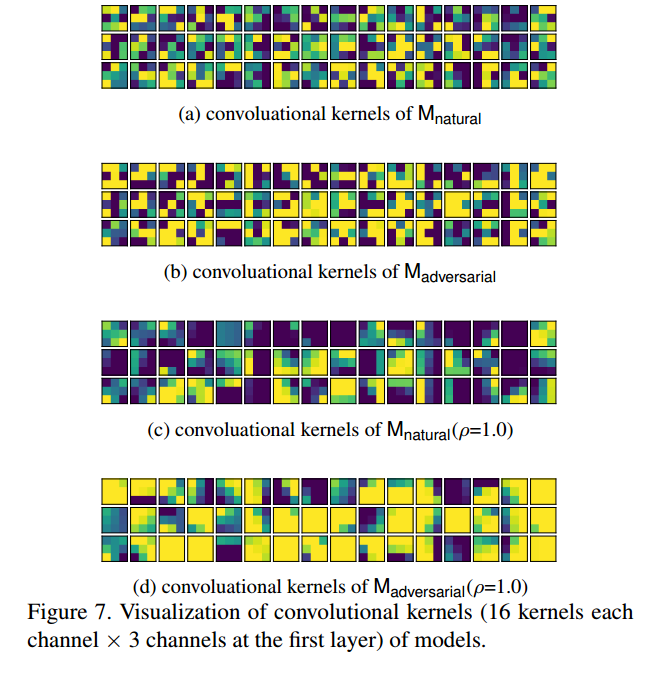
可以发现经过对抗样本训练后的模型,卷积核参数更加平衡(相邻位置的权重非常相似)。通过以前的论文也可以证明平滑卷积核能够有效地移除高频信号,从本文假设来理解上述现象就是一个非常自然的想法了。
有了上述的论证,那么我们可以试图思考:如果我直接把卷积核平滑化是不是可以提高鲁棒性?为此作者采用了如下公式:
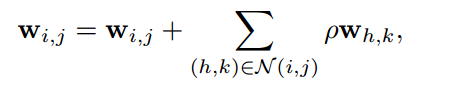
其实就是在每个位置的核参数都按照一定比例加上邻近位置的核参数,使得核参数平滑。效果如下所示:
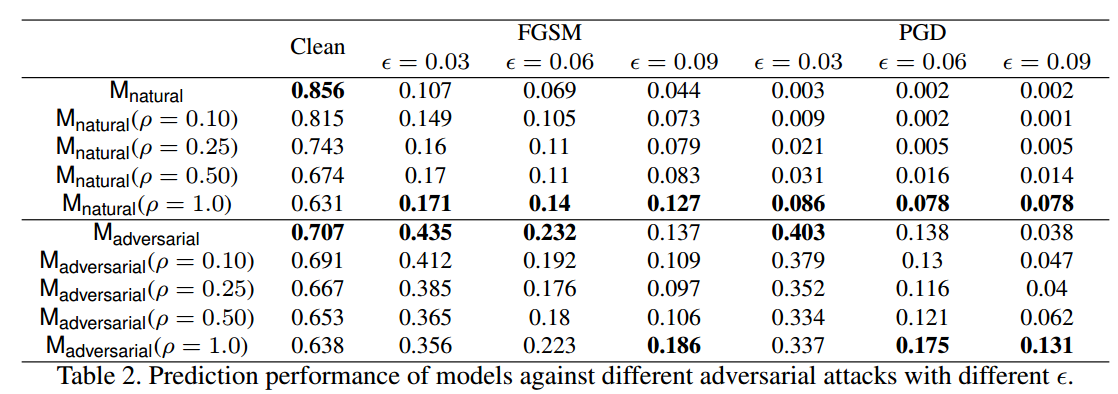
可以发现当应用平滑方法时,CNN精度的性能下降非常多,但是对抗鲁棒性提高了一点。这个小实验可以说明几点:
- 当核参数平滑后,会过滤掉图片的高频成分,导致acc急剧下降
- 核参数平滑后,可以提升一点点鲁棒性,说明高频信息是对抗攻击的一部分,但并非全部,可能还有其他因素
- CNN高频成分引入的多少,可能会导致精度和鲁棒性之间的平衡
总结
本文从数据的高低频成分角度分析,得出如下结论:
- CNN学习过程中会先尝试拟合低频信息,随着训练进行如果loss不再下降,则会进一步引入高频成分
- 高频成分不仅仅是噪声,还可能包含和数据分布特性相关信息,但是CNN无法针对性的选择利用,如果噪声引入的程度比较多则会出现过拟合,泛化能力下降
- 暂时没有一个好手段去除高频成分中的噪声,目前唯一能做的就是尝试用合适的半径阈值r去掉高频成分,防止噪声干扰,同时测试也需要进行相应去高频操作,或许可以提升泛化能力
- mix-up、BN、对抗样本和早停止等提点组件都可以促进CNN尽可能快且多的利用高频成分,从而提升性能
- 对抗鲁棒性较好的模型卷积核更加平滑,可以利用该特性稍微提高下CNN的鲁棒性
最后重申一句:人类标注时候仅仅是考虑低频语义信息,而CNN学习会考虑额外的高频成分,从而学习出的模型表现有时候不符合人类想法,这不是bug,也不是CNN垃圾,而是大家看到的和想的不一样。
噪声label学习
论文名称:Identifying Mislabeled Data using the Area Under the Margin Ranking
github:https://github.com/Manuscrit/Area-Under-the-Margin-Ranking
论文思想
论文目的主要是找出错误标注数据。主要创新包括:
(1) 提出了aum分值 Area Under the Margin来区分正确和错误标注样本 (2) 由于aum分值是和数据集相关的,阈值切分比较关键,故作者提出指示样本indicator samples的概念来自动找到最合适的aum阈值
Not all data in a typical training set help with generalization
AUM的定义非常简单:
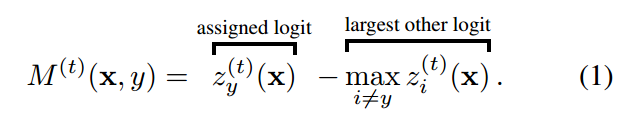
对于任何一个样本,z是指softmax预测概率值,zy是指的分配label位置对应的预测输出值,max zi是指除了label位置预测输出最大值。当样本label正确时候,该值比较大,当label不正确的时候,该值比较小甚至是负数。
利用该特性就可以把错误标签样本找出来。仅仅计算样本当前epoch时候的AUM值不太靠谱,一个错误样本应该aum值都差不多,故作者采用了所有epoch的aum平均值:
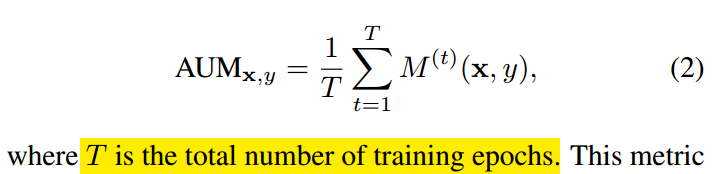
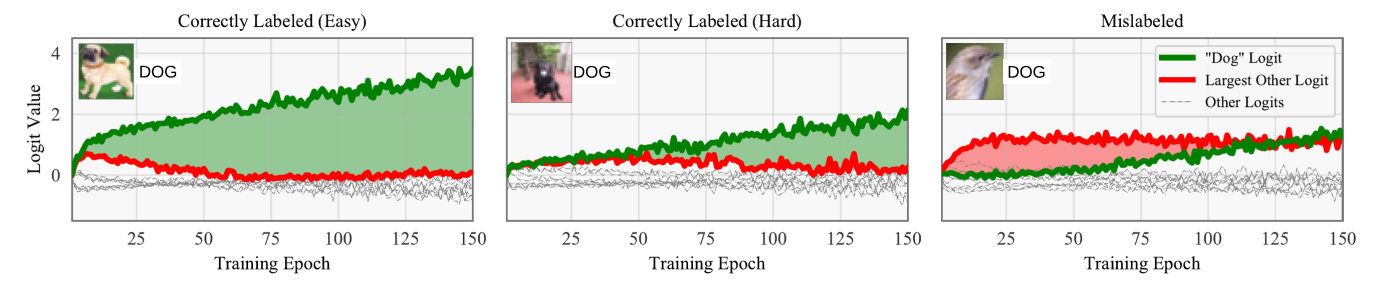
中间的绿色区域就是AUM。
基于上述办法可以得到每个样本的AUM值,但是如何设置阈值来确定噪声样本?本文提出Indicator Samples概念自动确定阈值。
做法其实非常简单:挑选一部分正确label数据,然后把这些数据全部算作c+1类,相当于在原始类别基础上扩展一个类,可以发现这些样本数据其实全部算是错误label数据,可以利用这部分数据的aum值来作为阈值。
-
ShuffleNet
ShuffleNetV1
论文名称:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
主要贡献
ShuffleNet是face++在MobileNetV1思想基础上提出的移动端模型。前面说过MobileNetV1主要是通过深度可分离卷积来减少参数和计算量,并且深度可分离卷积实际上包括逐通道分离卷积和1x1标准点卷积两个模块,由于通常输入和输出通道比较大,故MobileNetV1的主要参数和计算量在于第二步的1x1标准逐点卷积
ShuffleNet主要改进是对1x1标准逐点卷积的计算量和参数量进一步缩减,具体是引入了1x1标准逐点分组卷积,但是分组逐点卷积会导致组和组之间信息无法交流,故进一步引入组间信息交换机制即shuffle层。通过上述两个组件,不仅减少了计算复杂度,而且精度有所提升。
算法设计
channel shuffle
当直接对1x1标准逐点卷积进行改进,变成1x1标准逐点分组卷积,通过将卷积运算的特征图限制在每个组内,模型的计算量可以显著下降。然而这样做带来了明显问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换,这将可能影响到模型的表示能力和识别精度。因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制,如下所示:
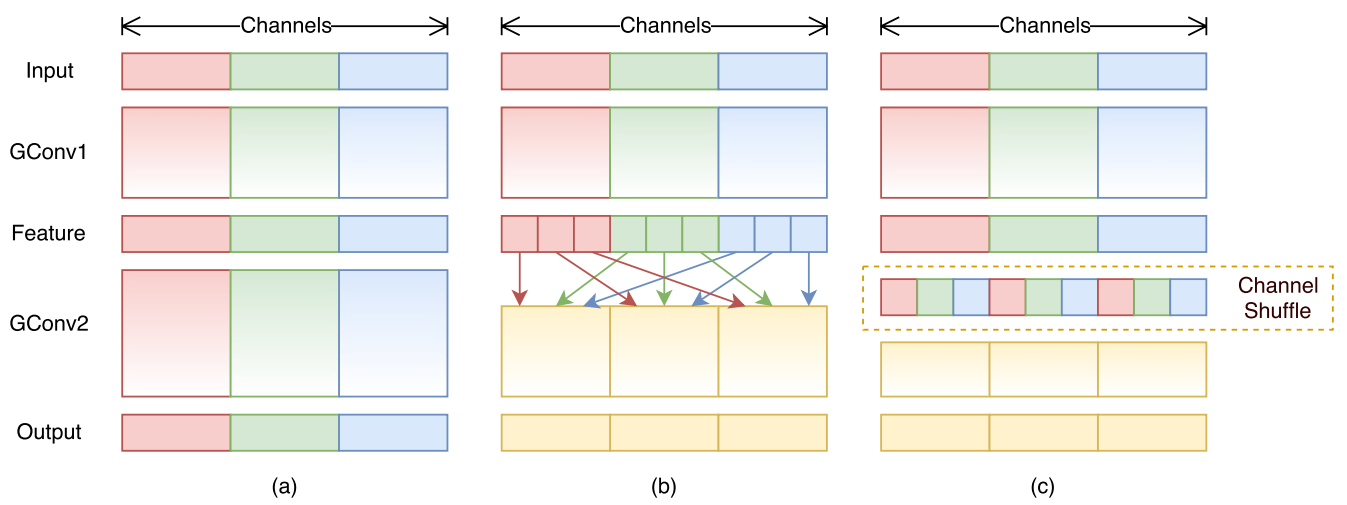
(a)图是堆叠多个分组卷积,组和组之间没有信息流通,这肯定会影响到模型的表示能力和识别精度,故可以在两个分组卷积层直接引入特征图打乱操作,如图(b)所示,而(c)是本文提出的通道shuffle层,效果和(b)等jia,但是实现上更加高效,并且是可导的。
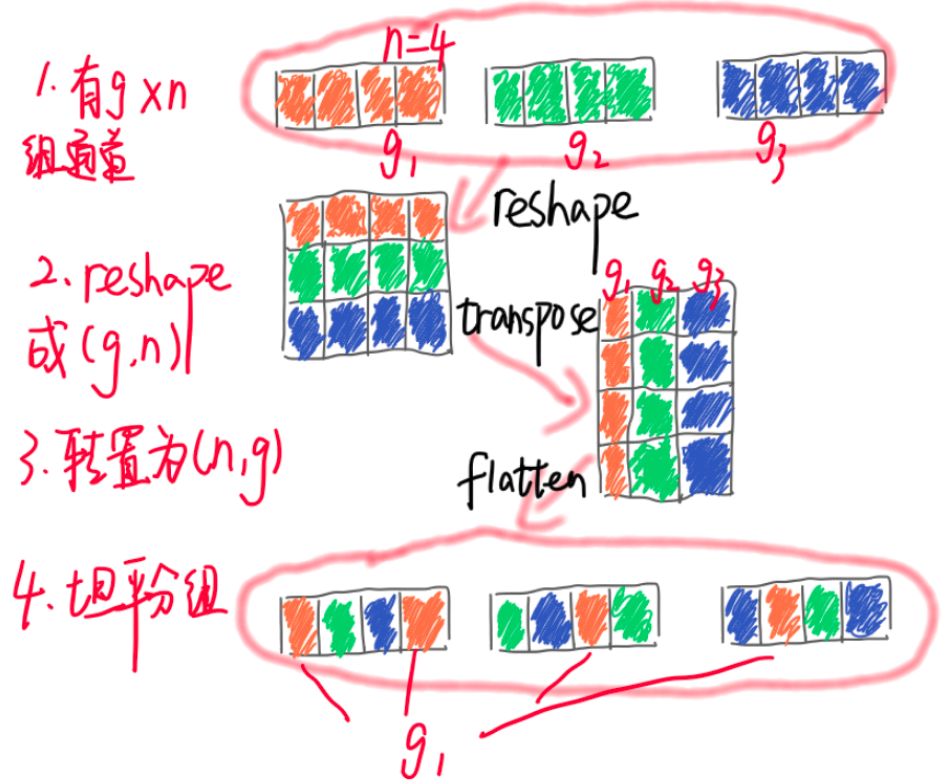
channel shuffle的实现非常简单,示意图如下:
核心就是先对输入特征图按照通道维度进行分组,然后转置,最后变成原始输入尺度即可。
ShuffleNet单元
基于上述所提组件,可以构建基础的shufflenet单元:
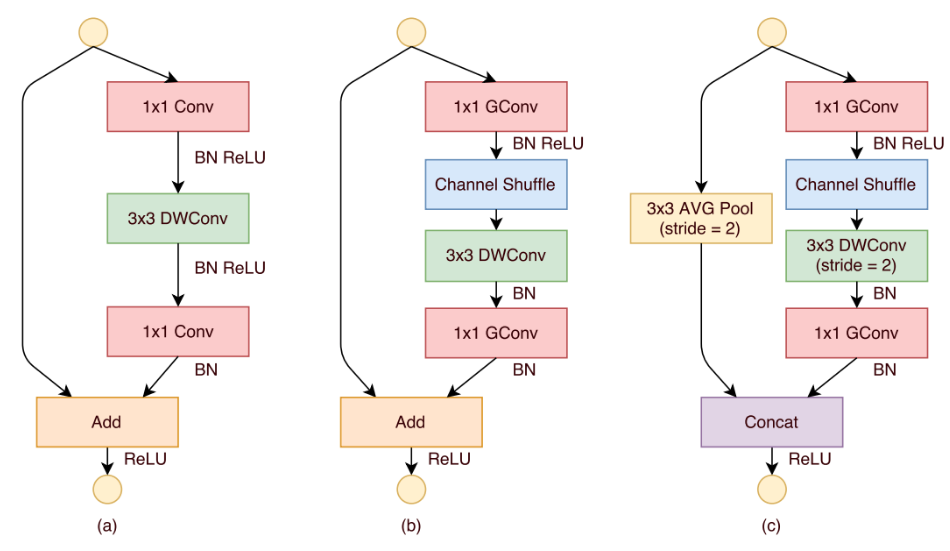
(a)是带有深度可分离卷积的bottleneck单元;(b)是设计的stride=1时候的shuffle单元;(c)是设计的stride=2时候的shuffle单元,在该单元中,使用concat来使得通道加倍,导致信息不缺失。
总结
shufflenetv1好于mobilenetv1,原因是: (1) 引入了残差结构 (2) 用了很多分组卷积,导致在同样FLOPS情况下,通道数可以多一些,模型复杂度比mobilenet低
shufflenet核心改进就是针对1x1逐点分组卷积存在的组内信息无法交互问题而提出了通道shuffle操作,并且通过实验发现在分组数增加情况下,可以显著减低计算复杂度,从而可以通过增加通道来实现比mobilenet精度更高且速度更快的模型功能。由于后续有新提出的shufflenetv2,故shufflenetv1现在用的也比较少。
ShuffleNetV2
论文名称:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
主要贡献
shufflenetv2论文最大贡献不是提出了一个新的模型,而是提出了4条设计高效CNN的规则,该4条规则考虑的映射比较多,不仅仅FLOPS参数,还可以到内存使用量、不同平台差异和速度指标等等,非常全面。在不违背这4条规则的前提下进行改进有望设计出速度和精度平衡的高效模型。
算法核心
到目前为止,前人所提轻量级CNN框架取得了很好效果,例如Xception、MobileNet、MobileNetV2和ShuffleNetv1等,主要采用技术手段是分组卷积Group convolution和逐深度方向卷积depthwise convolution。
在上述算法中,除了精度要求外,评价模型复杂度都是采用FLOPs指标(每秒浮点加乘运算次数),在mobilnetv1、v2和ShuffleNet都是采用该指标的。然而FLOPs 其实是一种间接指标,它只是真正关心的直接指标(如速度或延迟)的一种近似形式,通常无法与直接指标划等号。先前研究已对这种差异有所察觉,比如MobileNet V2要远快于 NASNET-A(自动搜索出的神经网络),但是两者FLOPs相当,它表明FLOPs近似的网络也会有不同的速度。所以,将FLOPs作为衡量计算复杂度的唯一标准是不够的,这样会导致次优设计。
研究者注意到FLOPs仅和卷积部分相关,尽管这一部分需要消耗大部分的时间,但其它过程例如数据 I/O、数据重排和元素级运算(张量加法、ReLU 等)也需要消耗一定程度的时间。
间接指标(FLOPs)和直接指标(速度)之间存在差异的原因可以归结为两点:
- 对速度有较大影响的几个重要因素对FLOPs不产生太大作用,例如内存访问成本 (MAC)。在某些操作(如组卷积)中,MAC占运行时间的很大一部分,对于像GPU这样具备强大计算能力的设备而言,这就是瓶颈,在网络架构设计过程中,内存访问成本不能被简单忽视
- 并行度。当FLOPs相同时,高并行度的模型可能比低并行度的模型快得多
其次,FLOPs相同的运算可能有着不同的运行时间,这取决于平台。例如,早期研究广泛使用张量分解来加速矩阵相乘。但是,近期研究发现张量分解在GPU上甚至更慢,尽管它减少了75%的 FLOPs。本文研究人员对此进行了调查,发现原因在于最近的 CUDNN库专为3×3 卷积优化:当然不能简单地认为3×3卷积的速度是1×1卷积速度的1/9。
总结如下就是:
- 影响模型运行速度还有别的指标,例如MAC(memory access ),并行度(degree of parallelism)
- 不同平台有不同的加速算法,这导致flops相同的运算可能需要不同的运算时间。
据此,提出了高效网络架构设计应该考虑的两个基本原则:第一,应该用直接指标(例如速度)替换间接指标(例如 FLOPs);第二,这些指标应该在目标平台上进行评估。在这项研究中,作者遵循这两个原则,并提出了一种更加高效的网络架构。
4条高效网络设计原则
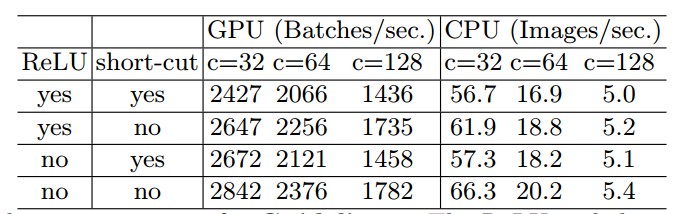
G1. 相同的通道宽度可最小化内存访问成本(MAC) 假设内存足够大一次性可存储所有特征图和参数;卷积核大小为1 * 1 ;输入通道有c1个;输出通道有c2个;特征图分辨率为h * w,则在1x1的卷积上,FLOPS:$B=hwc1c2$,MAC:$hw(c1+c2)+c1c2$,容易推出: \(MAC>2\sqrt{hwB}+\frac{B}{hw}\) MAC是内存访问量,hwc1是输入特征图内存大小,hwc2是输出特征图内存大小,c1xc2是卷积核内存大小。从公式中我们可以得出MAC的一个下界,即当c1==c2 时,MAC取得最小值。以上是理论证明,下面是实验证明:
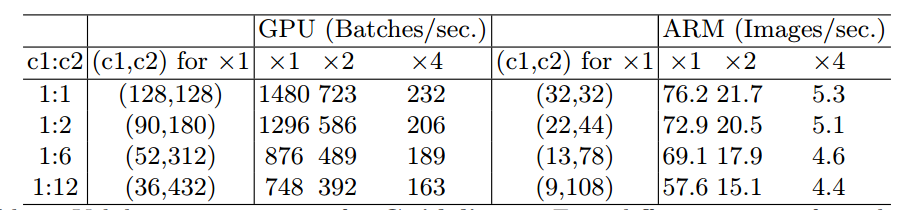
可以看出,当c1==c2时,无论在GPU平台还是ARM平台,均获得了最快的runtime。
G2. 过度使用组卷积会增加MAC 和(1)假设一样,设g表示分组数,则有: \(MAC=hw(c_1+c_2)+\frac{c_1c_2}{g}\\ =hwc_1+\frac{Bg}{c_1}+\frac{B}{hw}\) 其中$B=hwc_1c_2$,当固定c1 w h和B,增加分组g,MAC也会增加,证明了上述说法。其中c1 w h固定,g增加的同时B复杂度也要固定,则需要把输出通道c2增加,因为g增加,复杂度是要下降的。以上是理论证明,下面是实验证明:
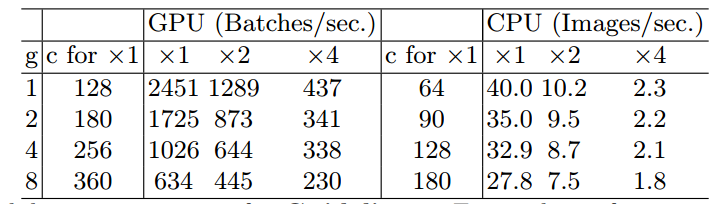
可以看出,g增加,runtime减少。
G3. 网络碎片化(例如 GoogLeNet 的多路径结构)会降低并行度 理论上,网络的碎片化虽然能给网络的accuracy带来帮助,但是在平行计算平台(如GPU)中,网络的碎片化会引起并行度的降低,最终增加runtime,同样的该文用实验验证:
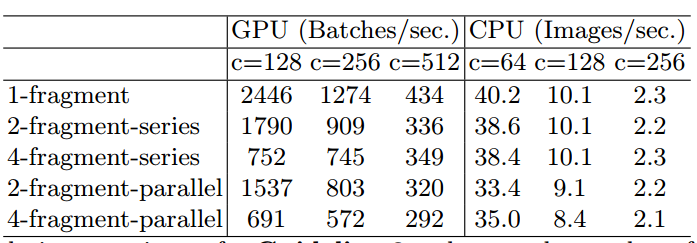
可以看出,碎片化越多,runtime越大。
G4. 元素级运算不可忽视
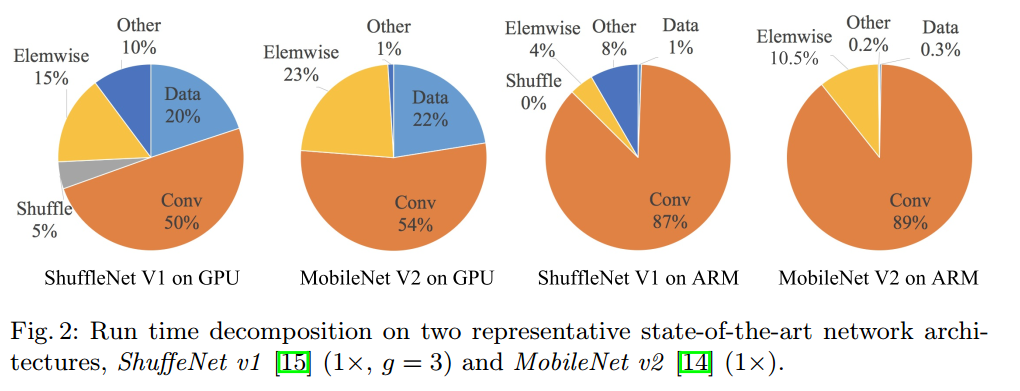
element-wise operations也占了不少runtime,尤其是GPU平台下,高达15%。ReLU、AddTensor及AddBias等这一类的操作就属于element-wise operations. 这一类操作,虽然flops很低,但是MAC很大,因而也占据相当时间。同样地,通过实验分析element-wise operations越少的网络,其速度越快。
以上就是作者提出的4点设计要求,总结如下
- 1x1卷积进行平衡输入和输出的通道大小
- 组卷积要谨慎使用,注意分组数
- 避免网络的碎片化
- 减少元素级运算
结合上述4点可以对目前移动端网络进行分析:
- ShuffleNetV1严重依赖组卷积(违反G2)和瓶颈形态的构造块(违反 G1)
- MobileNetV2使用倒置的瓶颈结构(违反G1),并且在“厚”特征图上使用了深度卷积和 ReLU激活函数(违反了G4)
- 自动生成结构的碎片化程度很高,违反了G3
算法模型
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。
基于以上缺点,作者重新设计了v2版本。V2主要结构是多个blocks堆叠构成,block又分为两种,一种是带通道分离的Channel Spilit,一种是带Stride=2。图示如下:
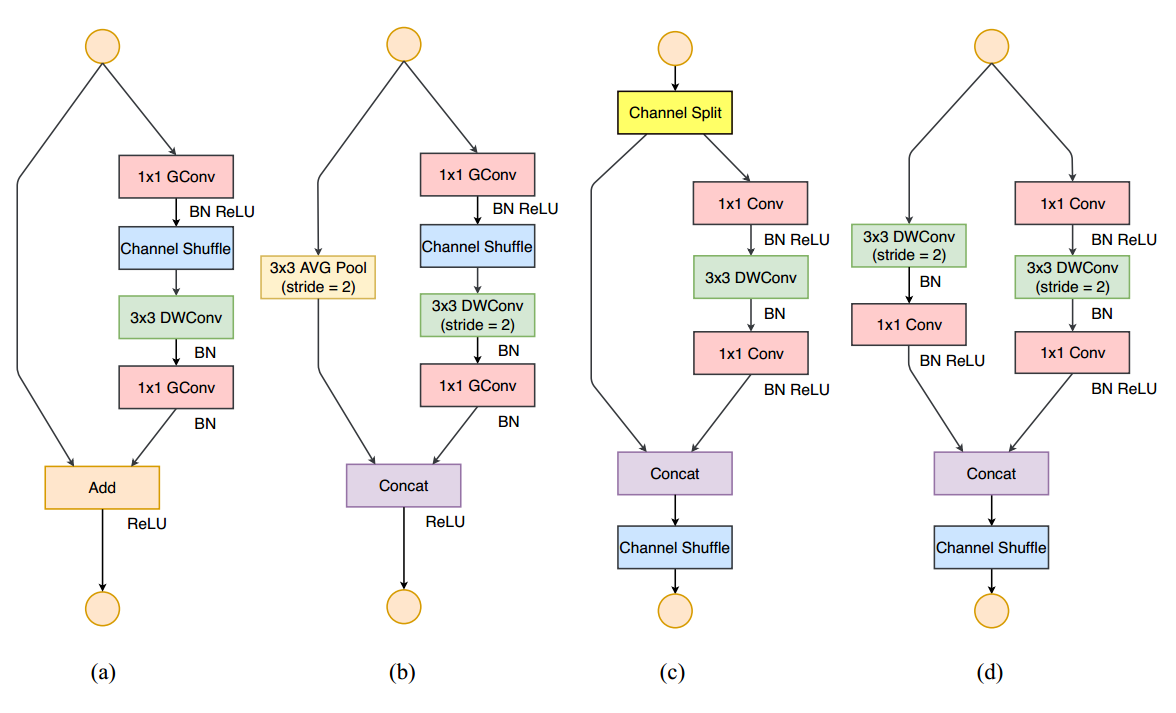
(a)为v1中的stride=1的block,(b)为v1中的stride=2的block,(c)是新设计的v2中的stride=1的block,(d)是新设计的v2中的stride=2的block。
在每个单元开始,c 特征通道的输入被分为两支,分别占据c−c’和c’个通道(一般设置c=c’*2)。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于stride=2的模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
总结
shufflenetv2针对目前移动端模型都仅仅考虑精度和FLOPS参数,但是这两个参数无法直接反映真正高效网络推理要求,故作者提出了4条高效网络设计准则,全面考虑了各种能够影响速度和内存访问量的因素,并给出了设计规则。再此基础上设计了shufflenetv2,实验结果表明速度和精度更加优异。