Welcome to My Blog!
这里记录着我的CV学习之路-
MobileNet
MobileNetV1
论文名称:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
主要贡献
提出的深度可分离卷积(depthwise separable convolutions)操作是现在移动端压缩模型的基本组件,在此基础上通过引入宽度因子(width multiplier)和分辨率因子(resolution multiplier)来构建不同大小的模型以适应不同场景精度要求。
-
GhostNet
GhostNet
论文名称:GhostNet: More Features from Cheap Operations
GitHub:https://github.com/huawei-noah/ghostnet
主要贡献
从特征图冗余问题出发,提出一个仅通过少量计算就能生成大量特征图的结构Ghost Module。
算法设计
在优秀CNN模型中,特征图存在冗余是非常重要的,但是很少有人在模型结构设计上考虑特征图冗余问题(The redundancy in feature maps)。
而本文就从特征图冗余问题出发,提出Ghost Module仅通过少量计算(cheap operations)就能生成大量特征图。经过线性操作生成的特征图称为ghost feature maps,而被操作的特征图称为intrinsic feature maps。
问题1: 何为特征图冗余?
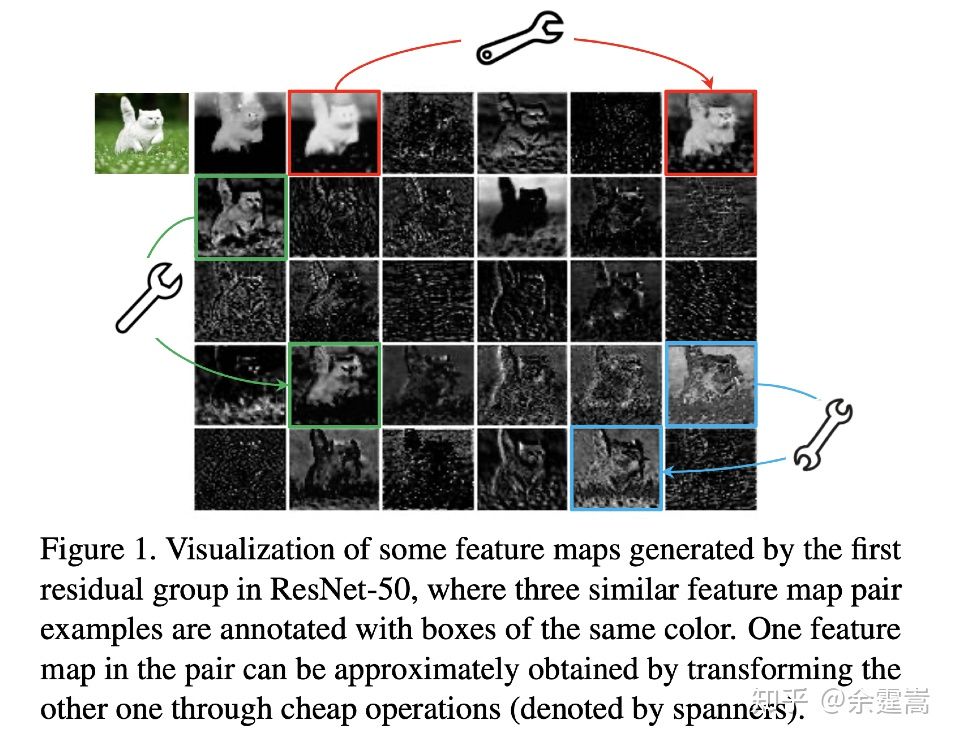
看着相似的那些就是冗余,作者用红绿蓝重点给我们标记的那些就是冗余特征图的代表
问题2: Ghost feature maps 和 Intrinsic feature maps 是什么?
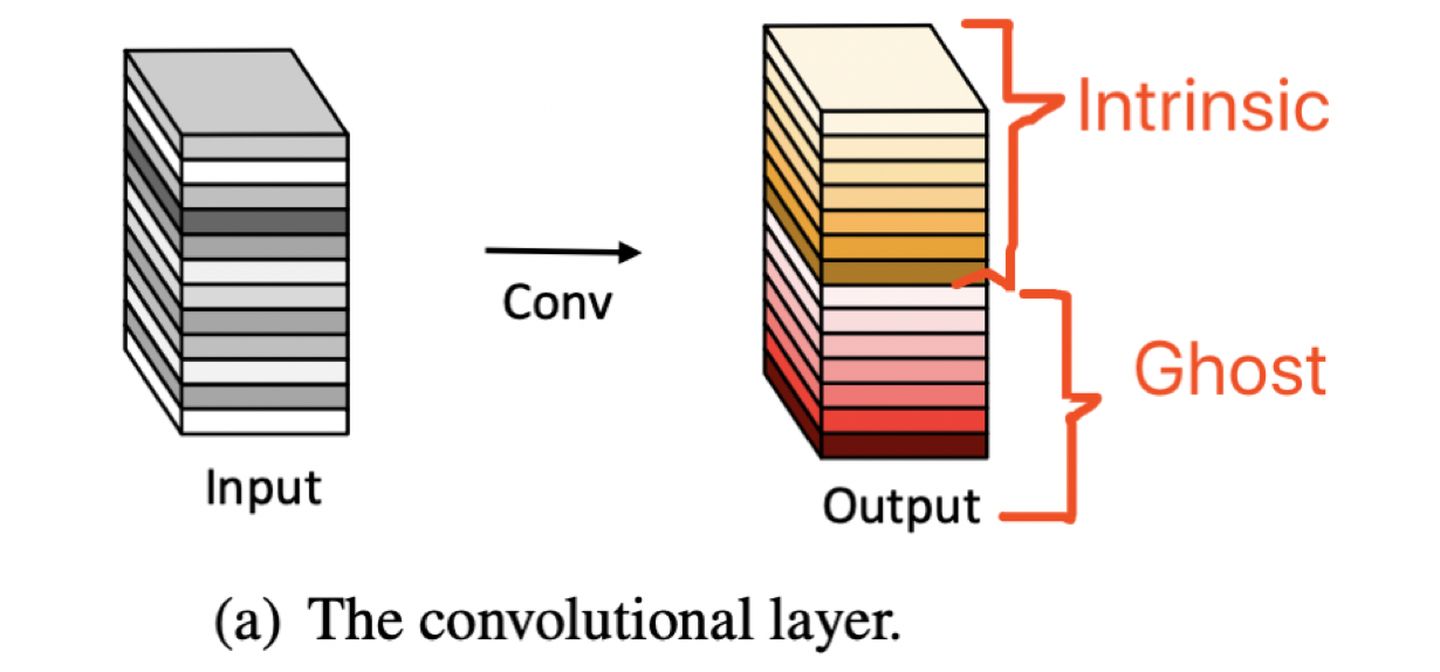
一组特征图中,一部分是Intrinic,而另外一部分是可以由 intrinsic 通过cheap operations来生成的。
问题3: Linear transformations 和 Cheap operations 是什么?
linear operations 等价于 cheap operations即是 诸如3 * 3的卷积,或者5 * 5的卷积。
问题4: Ghost Module长什么样?Ghost Bottlenecks长什么样?Ghost Net长什么样?
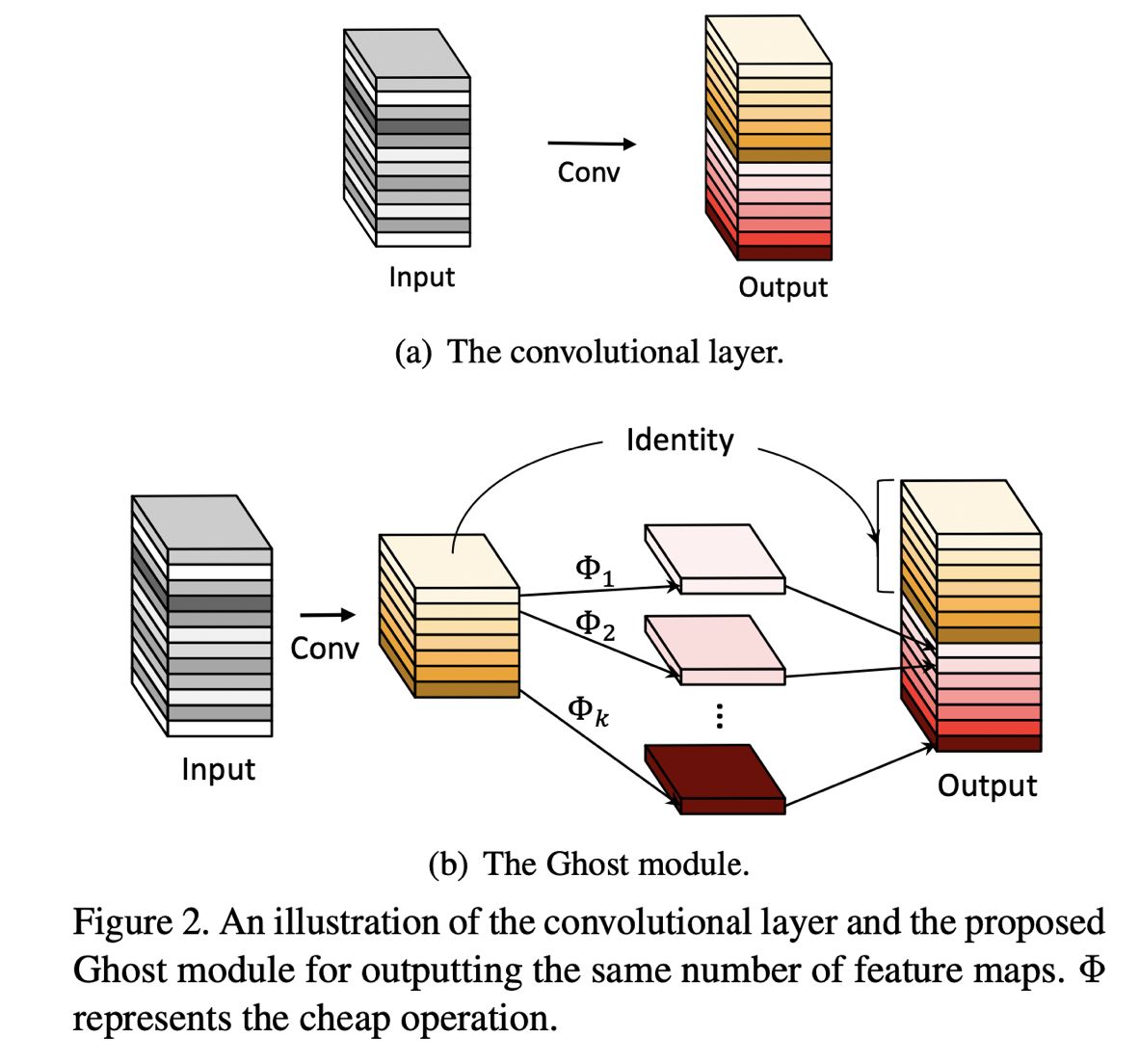
通常的卷积如图2(a)所示,而Ghost Module则分为两步操作来获得与普通卷积一样数量的特征图(这里需要强调,是数量一样)。
第一步:少量卷积(比如正常用32个卷积核,这里就用16个,从而减少一半的计算量)
第二步:cheap operations,如图中的Φ表示,从问题3中可知,Φ是诸如3*3的卷积,并且是逐个特征图的进行卷积(Depth-wise convolutional)。
这里应该是本文最大的创新点和贡献了。
了解了Ghost Module,下面看Ghost Bottlenecks。
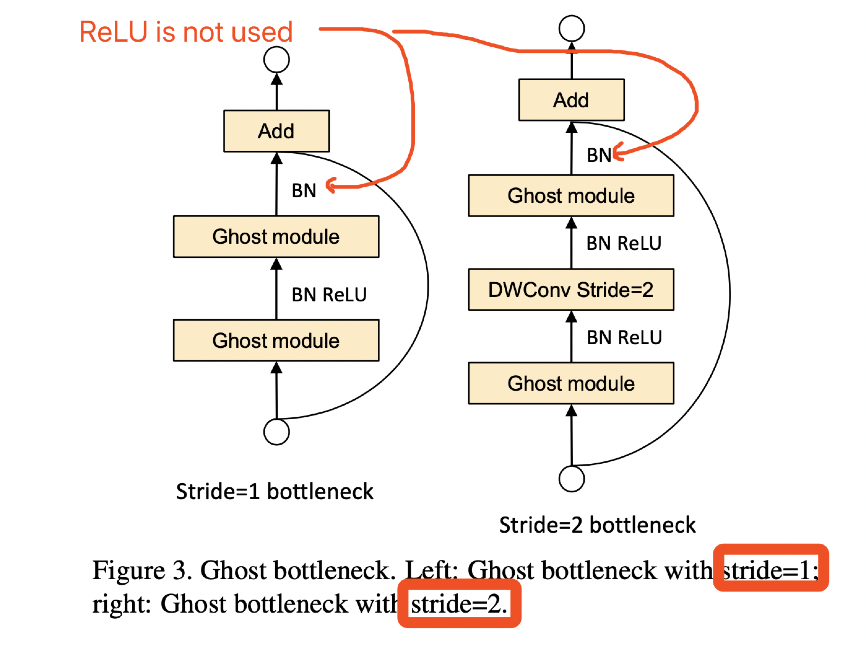
结构与ResNet的是类似的,并且与mobilenet-v2一样在第二个module之后不采用ReLU激活函数。
左边是stride=1的Ghost Bottlenecks,右边是stride=2的Ghost Bottlenecks,目的是为了缩减特征图大小。
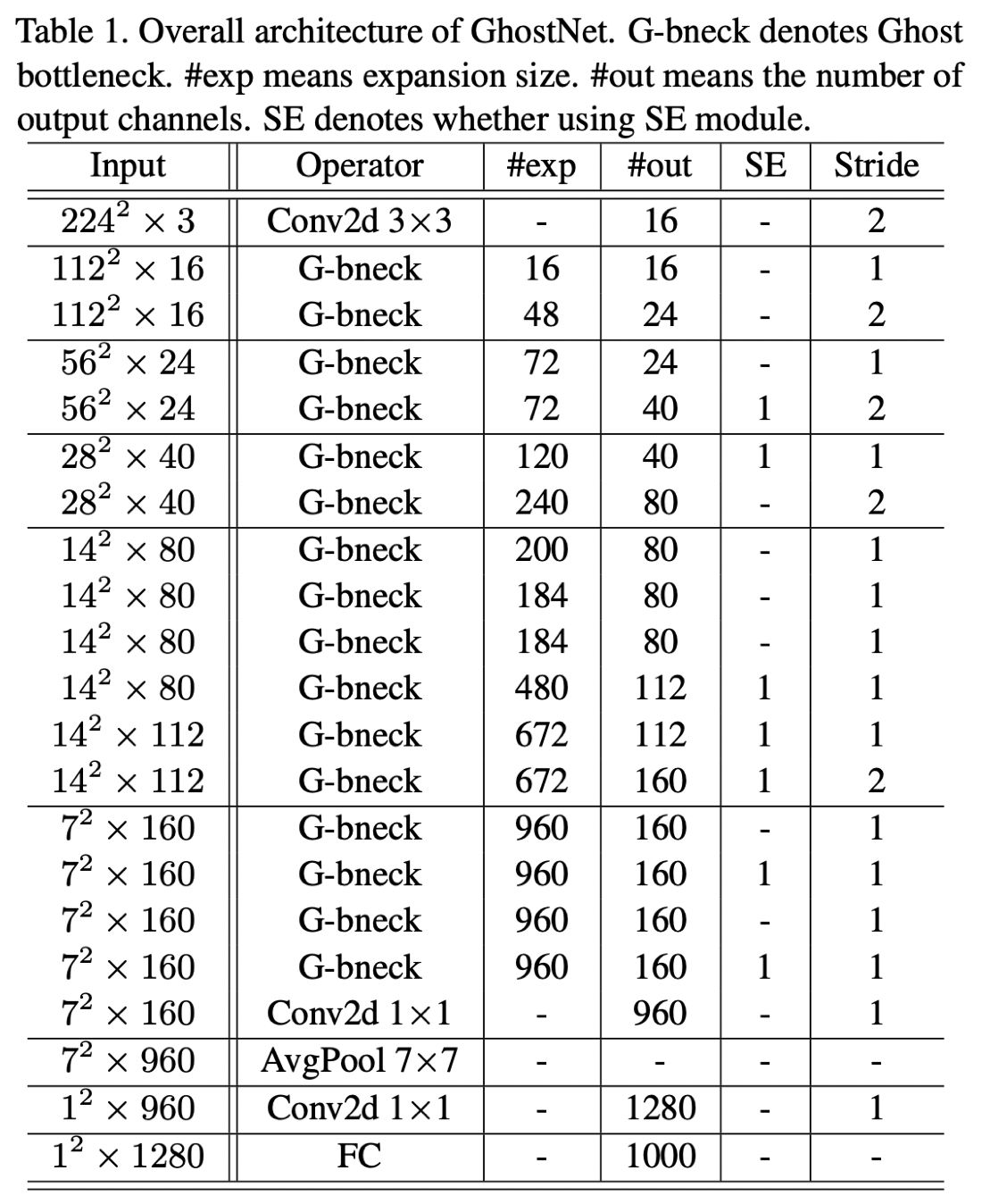
接着来看Ghost Net,Ghost Net结构与MobileNet-V3类似,并且用了SE结构,如下表,其中#exp表示G-bneck的第一个G-Module输出特征图数量
总结
Ghost Module的想法很巧妙,可即插即用的实现轻量级卷积模型,但若能实现不训练的轻量级卷积模型,那就更好了。这也是本笔记中遗憾的部分,未能实现不训练的即插即用,在此希望集思广益,改进上述提出的不成熟方案,说不定GhostNet-V2就诞生了,当然更期待原作者提出GhostNet-V2。
-
损失函数-人脸识别
人脸识别
在人脸识别的任务中,特征不仅仅是要可分,而且还要能够容易判别,如下图,左边的特征虽然可分,但是类间距离不够大,因此会导致错分现象,而好的特征应该像右图那样,很容易区分。 即减小类内距离,增加类间距离。
在人脸认证任务中,常用的步骤是通过提取网络最后一层特征,通过计算余弦或者欧式距离进行判断。

Center Loss
论文链接:A Discriminative Feature Learning Approach for Deep Face Recognition
代码链接:https://github.com/ydwen/caffe-face
主要贡献
Softmax函数学习到的特征仍然有很大的类内差距,提出了一种新的辅助损失函数(center loss),结合 softmax交叉熵损失函数,在不同数据及上提高识别准确率。
Sotfmax损失函数公式:
\[L_S=-\sum_{i=1}^{m}\log{\frac{e^{W_{y_i}^T x_i+b_{y_i}}}{\sum_{j=1}^{n} e^{W_j^T x_i+b_j}}}\]Softmax使得每一类可分,关注的是类间的距离,但并没有关注类内的问题。因此作者希望在每一个batch中,每一个样本都能向同一类的中心靠拢。即在分类时,也要向类心靠近,Loss如下:
\[L_C=\frac{1}{2}\sum_{i=1}^{m}\left \| x_i-c_{y_i} \right \|_2^2\]$C_{y_i}$表示属于$y_i$类的特征的中心。
这样做是存在问题的:
理想情况下,我们每次更新权值都要遍历全部的训练集去获得每个类的中心,这是低效甚至不实际的
为了解决这个问题,作者使用了minbatch中的每个类的中心来更新,(虽然这样可能有些类的中心在一次迭代中无法更新到)
\[\Delta c_j=\frac{\sum_{i=1}^{m}\delta(y_i=j)\cdot(c_j-x_i) }{1+\sum_{i=1}^{m}\delta(y_i=j)}\]总损失函数使用的是Softmax+center Loss联合损失:
\[L=L_S+\lambda L_C =-\sum_{i=1}^{m}\log{\frac{e^{W_{y_i}^T x_i+b_{y_i}}}{\sum_{j=1}^{n} e^{W_j^T x_i+b_j}}}+ \frac{\lambda}{2}\sum_{i=1}^{m}\left \| x_i-c_{y_i} \right \|_2^2\]求导:
\[\frac{\partial{L_C}}{\partial {x_i}}=x_i-c_{y_i}\]算法流程类似一般的卷积神经网络,就是多了一个更新中心点的流程。
NormFace
论文链接:NormFace: L2 Hypersphere Embedding for Face Verification
主要贡献
解决了4个问题:
1.为什么在测试时必须要归一化?
2.为什么直接优化余弦相似度会导致网络不收敛?
3.怎么样使用softmax loss优化余弦相似度
4.既然softmax loss在优化余弦相似度时不能收敛,那么其他的损失函数可以收敛吗?
问题分析
之前的人脸识别工作,在特征比较阶段,通常使用的都是特征的余弦距离,而余弦距离等价于L2归一化后的内积,也等价L2归一化后的欧式距离(欧式距离表示超球面上的弦长,两个向量之间的夹角越大,弦长也越大)。然而,在实际上训练的时候用的都是没有L2归一化的内积
关于这一点可以这样解释,Softmax函数是:
\[P_{y_i}={\frac{e^{W_{y_i}^T x_i+b_{y_i}}}{\sum_{j=1}^{n} e^{W_j^T x_i+b_j}}}\]可以理解为$W_{y_i}$和特征向量$x_i$的内积越大,$x_i$属于第$y_i$类概率也就越大,训练过程就是最大化x与其标签对应项的权值$W_{label(x)}$的过程。
这也就是说在训练时使用的距离度量与在测试时使用的度量是不一样的。
作者实验说明进行人脸验证时使用归一化后的内积或者欧式距离效果明显会优于直接计算两个特征向量的内积或者欧式距离。

注意这个Normalization不同于batch normalization,一个是对L2范数进行归一化,一个是均值归零,方差归一。
是否可以直接在训练时也对特征向量归一化?
针对上面的问题,作者设计实验,通过归一化Softmax所有的特征和权重来创建一个cosine layer,实验结果是网络不收敛了。
问题1、2为什么必须要归一化和为什么直接优化归一化后的特征网络不会收敛
全连接层特征降至二维的MNIST特征图:
-
损失函数-目标检测
目标检测
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)-> CIoU Loss(2020)
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息
Smooth L1 Loss
Smooth L1 Loss能从两个方面限制梯度:当预测框与 ground truth 差别过大时,梯度值不至于过大;当预测框与 ground truth 差别很小时,梯度值足够小。
\[\begin{align} L_2(x) &= x^2 \\ L_1(x) &= x \\ smooth_{L_1}(x) &=\left \{ \begin{array}{c} 0.5x^2 & if \mid x \mid <1 \\ \mid x \mid - 0.5 & otherwise \end{array} \right. \end{align}\]损失对于$x$的导数为:
\[\begin{align} \frac{\partial L_2(x)}{\partial x} &= 2x \\ \frac{\partial L_1(x)}{\partial x} &= \left \{ \begin{array}{c} 1 & \text{if } x \geq 0 \\ -1 & \text{otherwise} \end{array} \right. \\ \frac{\partial smooth_{L_1}(x)}{\partial x} &=\left \{ \begin{array}{c} x & if \mid x \mid <1 \\ \pm1 & otherwise \end{array} \right. \end{align}\]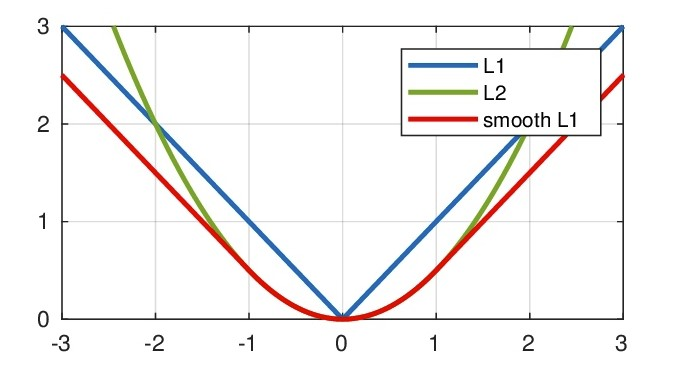
从损失函数对x的导数可知:L1损失函数对x的导数为常数,在训练后期,x很小时,如果learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。L2失函数对x的导数在x值很大时,其导数也非常大,在训练初期不稳定。 Smooth L1完美的避开了L1、L2损失的缺点。
IoU Loss
Smooth L1 loss不能很好的衡量预测框与ground true 之间的关系,相对独立的处理坐标之间的关系可能出现Smooth L1 loss相同,但实际IoU不同的情况。因此,提出IoU loss,将四个点构成的box看成一个整体进行损失的衡量$L_{IoU}=-\ln IoU(A,B)$也可定义为$1-IoU(A,B)$。IoU loss具有尺度不变性,大边界框的IoU loss 基本上与小边界框的IoU loss相等,本质上是对IoU的交叉熵损失,即将IoU视为伯努利分布的随机采样。
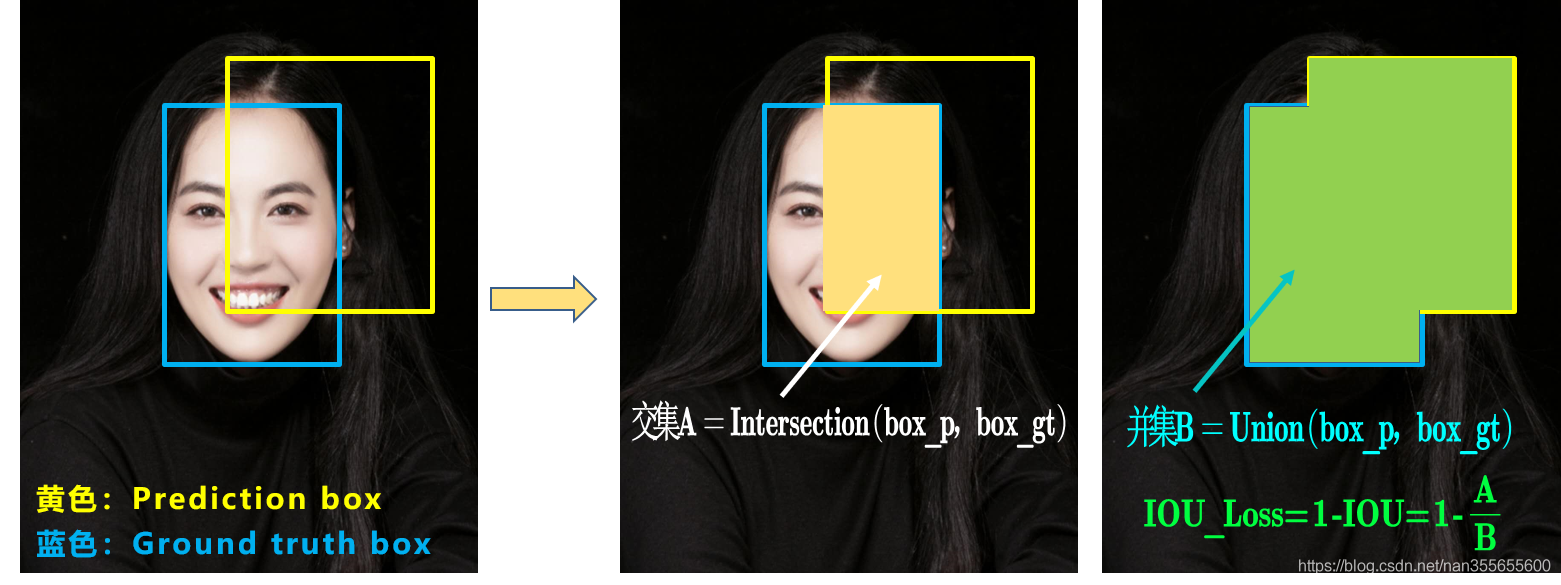

可以看到IoU的loss其实很简单,主要是交集/并集,但其实也存在两个问题
问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同、IOU也相同,IOU Loss无法区分两者相交情况的不同。
GIoU Loss
GIoU Loss中在原来的IOU损失的基础上加上一个惩罚项,就可以衡量预测框与真实框不相交的情况
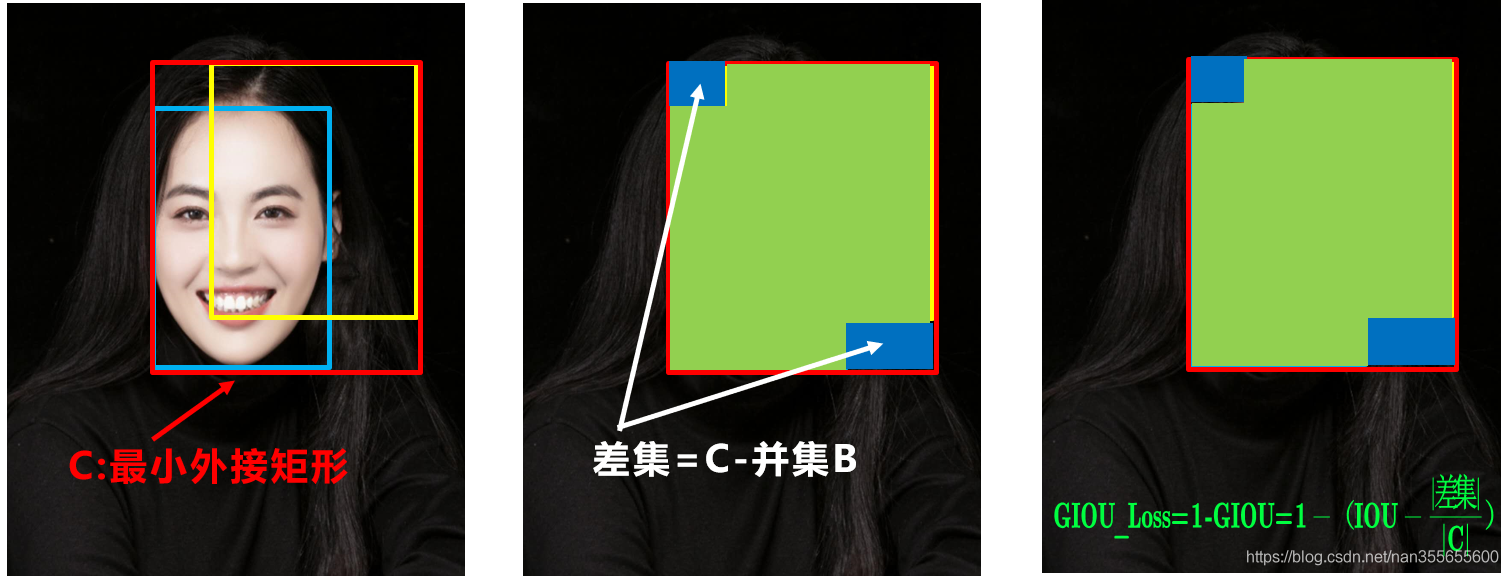

GIoU是IoU的下界,当且仅当两个框完全重合时相等,IoU取值范围为[0,1],GIoU取值范围为[-1,1],IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
DIoU Loss
DIOU_Loss考虑了重叠面积和中心点距离。 \(L_{DIoU}=1-(IoU-\frac{\rho^2(b,b^{gt})}{c^2})\) 其中$b$,$b^{gt}$分别表示$B$,$B^{gt}$的中心点$\rho(·)$为欧氏距离,$c$为$B$,$B^{gt}$的最小外接矩形的对角线距离。

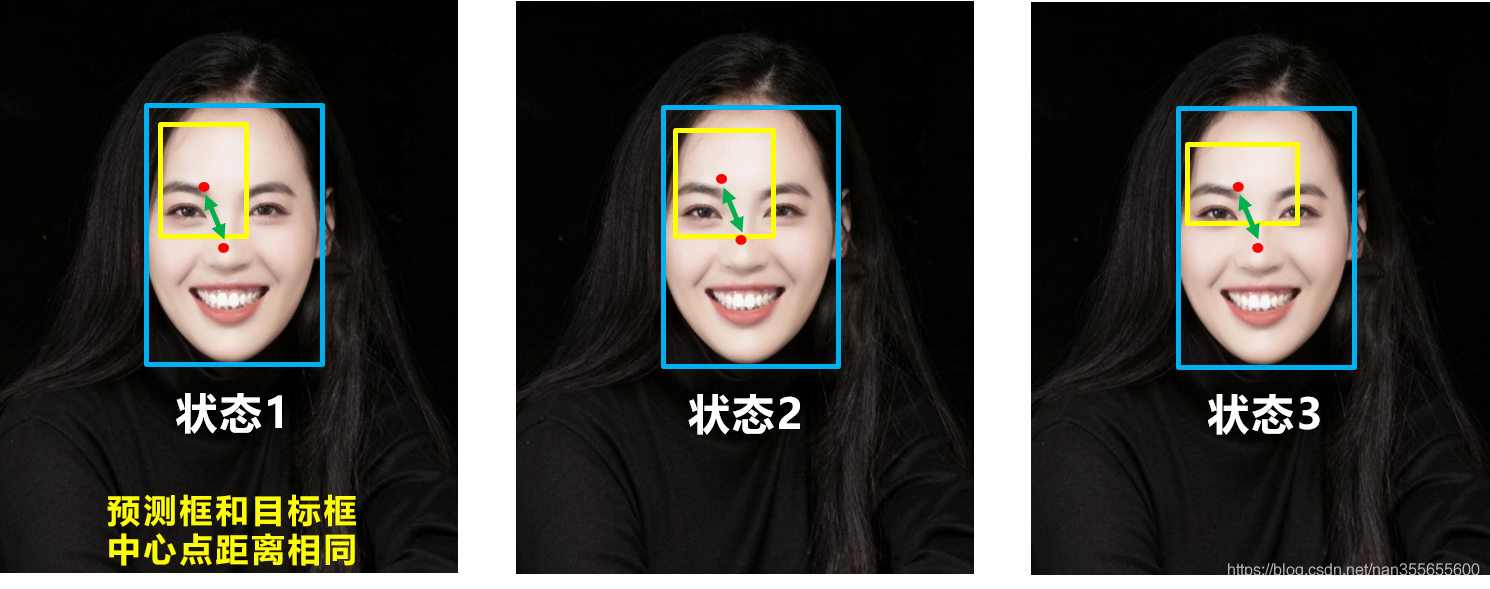
问题:比如上面三种状态,目标框包裹预测框,本来DIOU_Loss可以起作用。但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
CIoU Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子$\alpha\nu$,将预测框和目标框的长宽比都考虑了进去。 \(L_{CIoU}=1-(IoU-\frac{\rho^2(b,b^{gt})}{c^2}-\alpha\nu)\\ \alpha=\frac{\nu}{(1-IoU)+\nu}\\ \nu=\frac{4}{\pi^2}(\arctan{\frac{w^{gt}}{h^{gt}}}-\arctan{\frac{w}{h}})^2\) $\nu$是用来衡量长宽比一致性的参数。
-
ONNX-TensorRT
ONNX-TensorRT
第一部分:ONNX-TensorRT工程
Onnx-tensorrt工程是用来将onnx模型转成tensorrt可用trtmodel的工程,其中包含了解析onnx op的代码,也可以根据需要添加自定义op。
当然如果没有自定义层之类的修改也可以直接使用tensorrt中nvonnxparser.lib解析。
nvonnxparser库概览
nvonnxparser库的核心代码文件见CMakeLists.txt文件,如下:
set(IMPORTER_SOURCES NvOnnxParser.cpp ModelImporter.cpp builtin_op_importers.cpp onnx2trt_utils.cpp ShapedWeights.cpp ShapeTensor.cpp LoopHelpers.cpp RNNHelpers.cpp OnnxAttrs.cpp )最终,这些代码被编译成动态链接库nvonnxparser.so和静态链接库nvonnxparser_static.a
add_library(nvonnxparser SHARED ${IMPORTER_SOURCES}) target_include_directories(nvonnxparser PUBLIC ${ONNX_INCLUDE_DIRS} ${TENSORRT_INCLUDE_DIR}) target_link_libraries(nvonnxparser PUBLIC onnx_proto ${PROTOBUF_LIBRARY} ${TENSORRT_LIBRARY}) add_library(nvonnxparser_static STATIC ${IMPORTER_SOURCES}) target_include_directories(nvonnxparser_static PUBLIC ${ONNX_INCLUDE_DIRS} ${TENSORRT_INCLUDE_DIR}) target_link_libraries(nvonnxparser_static PUBLIC onnx_proto ${PROTOBUF_LIBRARY} ${TENSORRT_LIBRARY})解析流程解读
解析onnx文件流程,包含createParser和parseFromFile两部分,对应以下两行代码,不熟悉tensorrt解析的可以先简单了解一下再回来看
nvonnxparser::createParser(*network, gLogger)onnxParser->parseFromFile(source.onnxmodel().c_str(), 1)createParser是最外层接口,定义在
NvOnnxParser.h中,返回IParser/** \brief 创建一个解析器对象 * * \param network 解析器将写入的network * \param logger The logger to use * \return a new parser object or NULL if an error occurred * \see IParser */ #ifdef _MSC_VER TENSORRTAPI IParser* createParser(nvinfer1::INetworkDefinition& network, nvinfer1::ILogger& logger) #else inline IParser* createParser(nvinfer1::INetworkDefinition& network, nvinfer1::ILogger& logger) #endif { return static_cast<IParser*>( createNvOnnxParser_INTERNAL(&network, &logger, NV_ONNX_PARSER_VERSION)); }/** \class IParser * * \brief 用于将ONNX模型解析为TensorRT网络定义的对象 */ class IParser { public: /** 将序列化的ONNX模型解析到TensorRT网络中。这种方法的诊断价值非常有限。如果由于任何原因(例如不支持的IR版本、不支持的opset等)解析序列化模型失败,则用户有责任拦截并报告错误。到要获得更好的诊断,请使用下面的parseFromFile方法。 */ virtual bool parse(void const* serialized_onnx_model, size_t serialized_onnx_model_size, const char* model_path = nullptr) = 0; /** \brief 解析一个onnx模型文件,可以是一个二进制protobuf或者一个文本onnx模型调用里面的Parse方法 */ virtual bool parseFromFile(const char* onnxModelFile, int verbosity) = 0; /** \brief 检查TensorRT是否支持特定的ONNX模型 */ virtual bool supportsModel(void const* serialized_onnx_model, size_t serialized_onnx_model_size, SubGraphCollection_t& sub_graph_collection, const char* model_path = nullptr) = 0; /** \brief 考虑到用户提供的权重,将序列化的ONNX模型解析到TensorRT网络中 */ virtual bool parseWithWeightDescriptors( void const* serialized_onnx_model, size_t serialized_onnx_model_size, uint32_t weight_count, onnxTensorDescriptorV1 const* weight_descriptors) = 0; /** \brief 返回解析器是否支持指定的运算符 */ virtual bool supportsOperator(const char* op_name) const = 0; //... //... };nvonnxparser::createParser函数通过
return new onnx2trt::ModelImporter(network, logger),返回类ModelImporter,类ModelImporter继承IParser并重写了虚函数,。class ModelImporter : public nvonnxparser::IParser { protected: string_map<NodeImporter> _op_importers; virtual Status importModel(::ONNX_NAMESPACE::ModelProto const& model, uint32_t weight_count, onnxTensorDescriptorV1 const* weight_descriptors); private: ImporterContext _importer_ctx; RefitMap_t mRefitMap; std::list<::ONNX_NAMESPACE::ModelProto> _onnx_models; // Needed for ownership of weights int _current_node; std::vector<Status> _errors; public: ModelImporter(nvinfer1::INetworkDefinition* network, nvinfer1::ILogger* logger) : _op_importers(getBuiltinOpImporterMap()) , _importer_ctx(network, logger, &mRefitMap) { } //... //... }通过
_op_importers(getBuiltinOpImporterMap())调用builtin_op_importers.h中的getBuiltinOpImporterMap()得到所有onnx注册的op,builtin_op_importers中所有的op,都将以DEFINE_BUILTIN_OP_IMPORTER形式出现,只要按照名字和版本注册了,那么当你加载onnx的时候,都会被认识builtin_op_importers
- onnxmodel到trtmodel的parse代码。从onnxmodel的input出发,最后,输出trtmodel的输出tensor_ptr;
- onnx支持的builtin operators包括Conv, Argmax, Unsample,Relu等,具体可以参考operators.md文件;
- 文件中根据onnx层的类型名调用相应的DEFINE_BUILTIN_OP_IMPORTER(Conv), DEFINE_BUILTIN_OP_IMPORTER(Argmax), DEFINE_BUILTIN_OP_IMPORTER(Unsample), DEFINE_BUILTIN_OP_IMPORTER(Relu)等,从而完成对应层的onnx2trtmodel的parser。
parseFromFile解析入口
onnxParser->parseFromFile(source.onnxmodel().c_str(), 1),流程如下调用ModelImporter::parseFromFile开始做解析
然后调用到ModelImporter::parse
然后是ModelImporter::parseWithWeightDescriptors
然后是ModelImporter::importModel
然后是ModelImporter::importInputs,这里ModelImporter::importInput是控制输入的,如果想对onnx的输入尺寸做修改,请修改里面的trt_dims即可
然后是ModelImporter::parseGraph,这里会调用getBuiltinOpImporterMap函数,获得builtin_op_importers所有自定义op
解析时查询op,调用(*importFunc),跳转到DEFINE_BUILTIN_OP_IMPORTER(op)
const string_map<NodeImporter>& opImporters = getBuiltinOpImporterMap(); //... //... // Dispatch to appropriate converter. const NodeImporter* importFunc{nullptr}; if (opImporters.count(node.op_type())) { importFunc = &opImporters.at(node.op_type()); } else { LOG_INFO("No importer registered for op: " << node.op_type() << ". Attempting to import as plugin."); importFunc = &opImporters.at("FallbackPluginImporter"); } std::vector<TensorOrWeights> outputs; GET_VALUE((*importFunc)(ctx, node, nodeInputs), &outputs);这里importFunc类型是NodeImporter,定义的std::function,输入(ctx, node, nodeInputs)
typedef std::function<NodeImportResult( IImporterContext* ctx, ::ONNX_NAMESPACE::NodeProto const& node, std::vector<TensorOrWeights>& inputs)> NodeImporter;DEFINE_BUILTIN_OP_IMPORTER(op)通过宏定义
#define DECLARE_BUILTIN_OP_IMPORTER(op) \ NodeImportResult import##op( \ IImporterContext* ctx, ::ONNX_NAMESPACE::NodeProto const& node, std::vector<TensorOrWeights>& inputs) #define DEFINE_BUILTIN_OP_IMPORTER(op) \ NodeImportResult import##op( \ IImporterContext* ctx, ::ONNX_NAMESPACE::NodeProto const& node, std::vector<TensorOrWeights>& inputs);\ static const bool op##_registered_builtin_op = registerBuiltinOpImporter(#op, import##op); \ IGNORE_UNUSED_GLOBAL(op##_registered_builtin_op); \ NodeImportResult import##op( \ IImporterContext* ctx, ::ONNX_NAMESPACE::NodeProto const& node, std::vector<TensorOrWeights>& inputs)主要完成以下三项工作:
1、将onnx输入数据转化为trt要求的数据格式
2、建立trt层,层定义参考Nvinfer.h
3、计算trt输出结果
第二部分:自定义op流程
DEFINE_BUILTIN_OP_IMPORTER
plugin层定义
-
TensorRT C++调用
-
ONNX模型解析
ONNX
第一部分:ONNX结构分析与修改工具
ONNX结构分析
ONNX结构的定义基本都在这一个onnx.proto文件里面了,如何你对protobuf不太熟悉的话,可以先简单了解一下再回来看这个文件。当然我们也不必把这个文件每一行都看明白,只需要了解其大概组成即可,有一些部分几乎不会使用到可以忽略。
解析模型用到的结构主要如下:
- ModelProto:最高级别的结构,定义了整个网络模型结构;
- GraphProto:graph定义了模型的计算逻辑以及带有参数的node节点,组成一个有向图结构;
- NodeProto:网络有向图的各个节点OP的结构,通常称为层,例如conv,relu层;
- AttributeProto:各OP的参数,通过该结构访问,例如:conv层的stride,dilation等;
- TensorProto:序列化的tensor value,一般weight,bias等常量均保存为该种结构;
- TensorShapeProto:网络的输入shape以及constant输入tensor的维度信息均保存为该种结构;
- TypeProto:表示ONNX数据类型。
上述几个Proto之间的关系:
将ONNX模型load进来之后,得到的是一个
ModelProto,它包含了一些版本信息,生产者信息和一个非常重要的GraphProto;在
GraphProto中包含了四个关键的repeated数组-
node(NodeProto类型):存放着模型中的所有计算节点 -
input(ValueInfoProto类型):存放着模型所有的输入节点 -
output(ValueInfoProto类型):存放着模型所有的输出节点 -
initializer(TensorProto类型):存放着模型所有的权重
那么节点与节点之间的拓扑定义方式,每个计算节点都同样会有
input和output这样的两个数组(不过都是普通的string类型),通过input和output的指向关系,我们就能够利用上述信息快速构建出一个深度学习模型的拓扑图。最后每个计算节点当中还包含了一个AttributeProto数组,用于描述该节点的属性,例如Conv层的属性包含group,pads和strides等等,具体每个计算节点的属性、输入和输出参考这个Operators.md文档。需要注意的是,刚才所说的
GraphProto中的input输入数组不仅仅包含我们一般理解中的图片输入的那个节点,还包含了模型当中所有权重。举个例子,Conv层中的W权重实体是保存在initializer当中的,那么相应的会有一个同名的输入在input当中,其背后的逻辑应该是把权重也看作是模型的输入,并通过initializer中的权重实体来对这个输入做初始化(也就是把值填充进来)修改ONNX模型
解决问题的最好办法是从根源入手,也就是从算法同学那边的模型代码入手,我们需要告诉他们问题出在哪里,如何修改。但是也有一些情况是无法通过修改模型代码解决的,或者与其浪费那个时间,不如我们部署工程师直接在ONNX模型上动刀解决问题。
还有一种更dirty的工作是,我们需要debug原模型和转换后的ONNX模型输出结果是否一致(误差小于某个阈值),如果不一致问题出现在哪一层,现有的深度学习框架我们有很多办法能够输出中间层的结果用于对比,而据我所知,ONNX中并没有提供这样的功能;这就导致了我们的debug工作极为繁琐
所以如果有办法能够随心所欲的修改ONNX模型就好了。要做到这一点,就需要了解上文所介绍的ONNX结构知识了。
比如说我们要在网络中添加一个节点,那么就需要先创建相应的
NodeProto,参照文档设定其的属性,指定该节点的输入与输出,如果该节点带有权重那还需要创建相应的ValueInfoProto和TensorProto分别放入graph中的input和initializer中,以上步骤缺一不可。经过一段时间的摸索和熟悉,我写了一个小工具onnx-surgery并集成了一些常用的功能进去,实现的逻辑非常简单,也非常容易拓展。代码比较简陋,但是足以完成一些常见的修改操作
第二部分:各大深度学习框架如何转换到ONNX
(需要说明的是,由于深度学习领域发展迅速,本文提到的几个框架也在快速的迭代过程中,所以希望本文提到的一些坑和bug在未来的版本当中能够逐一解决,也希望大家永远不要踩本文所提到的那些坑)
MXNet转换ONNX
MXNet官方文档给出了一个非常简单的例子展示如何转换
import mxnet as mx import numpy as np from mxnet.contrib import onnx as onnx_mxnet import logging logging.basicConfig(level=logging.INFO) # Download pre-trained resnet model - json and params by running following code. path='http://data.mxnet.io/models/imagenet/' [mx.test_utils.download(path+'resnet/18-layers/resnet-18-0000.params'), mx.test_utils.download(path+'resnet/18-layers/resnet-18-symbol.json'), mx.test_utils.download(path+'synset.txt')] # Downloaded input symbol and params files sym = './resnet-18-symbol.json' params = './resnet-18-0000.params' # Standard Imagenet input - 3 channels, 224*224 input_shape = (1,3,224,224) # Path of the output file onnx_file = './mxnet_exported_resnet50.onnx' # Invoke export model API. It returns path of the converted onnx model converted_model_path = onnx_mxnet.export_model(sym, params, [input_shape], np.float32, onnx_file)这个重点提一下MXNet转换ONNX模型可能会遇到的一些问题,不排除在未来版本MXNet修复了相关问题,也不排除未来ONNX版本更新又出现新的不兼容问题。
转换中坑比较多,具体可参考
Insightface中ArcFace MxNet2ONNX踩坑
Insightface中Retinaface MxNet2ONNX踩坑
-
与MXNet的BatchNorm层中的fix_gamma参数有关,当fix_gamma参数为True时,其含义是将gamma这个参数固定为1,即(x-mean)/var * gamma + beta;但是这里就出现了不兼容的问题,因为在ONNX当中是没有fix_gamma这个属性的,如果fix_gamma为False不会有问题,如果fix_gamma为True就会出现两者计算结果不一致问题。解决方法很直观,当fix_gamma参数为True时,我们必须手动将ONNX当中的gamma参数全部置为1
-
与MXNet的Pooling层中的count_include_pad属性有关,这个问题应该是MXNet贡献者的疏忽,当Pooling层的类型为’avg’时,忘记了在生成ONNX节点时设置该属性。解决方法就是在_op_translation.py文件里增加一个分支,将这个遗漏属性补上。
count_include_pad = 1 if attrs.get("count_include_pad", "True") in ["True", "1"] else 0 # ... # ... # ... elif pool_type == "avg": node = onnx.helper.make_node( pool_types[pool_type], input_nodes, # input [name], count_include_pad=count_include_pad, kernel_shape=kernel, pads=pad_dims, strides=stride, name=name )- SoftmaxActivationm,在mxnet中,表明This operator has been deprecated.解决办法:手动修改SoftmaxActivation的op为softmax,axis=1对应channel。
当然,如果你不想直接修改MXNet的导出代码,也可以直接修改ONNX模型达到同样的目的,方法可以参考上一篇文章中的小工具
TensorFlow模型转ONNX
tf的模型转换ONNX已经有现成的转换工具,https://github.com/onnx/tensorflow-onnx,先将tf的模型freeze_graph之后得到pb文件,再利用该转换工具即可转换为onnx模型
freeze_graph的方式网上有很多版本,我这里用的是一个老版本的方法(tensorflow==1.8.0)
# your network def import network input_size = (224, 224) ckpt_model_path = "./model.ckpt" pb_model_path = "./model.pb" output_node_name = "your model output name" graph = tf.Graph() with graph.as_default(): placeholder = tf.placeholder( dtype=tf.float32, shape=[None, input_size[0], input_size[1], 3], name="pb_input" ) output = network(placeholder) # your can get all the tensor names if you do not know your input and output name in your ckpt with this code # nl = [n.name for n in tf.get_default_graph().as_graph_def().node] # for n in nl: # print(n) saver = tf.train.Saver() sess = tf.Session( config=tf.ConfigProto( gpu_options=tf.GPUOptions( allow_growth=True, per_process_gpu_memory_fraction=1.0), allow_soft_placement=True ) ) saver.restore(sess, ckpt_model_path) output_graph_def = graph_util.convert_variables_to_constants( sess, sess.graph_def, [output_node_name] ) with tf.gfile.FastGFile(pb_model_path, mode="wb") as f: f.write(output_graph_def.SerializeToString()) # you can get the input and output name of your model.pb file # maybe a "import/" is needed to append before the name if you # get some error # gf = tf.GraphDef() # gf.ParseFromString(open('./model.pb', 'rb').read()) # nl2 = [n.name + '=>' + n.op for n in gf.node if n.op in ('Softmax', 'Placeholder')] # for n in nl2: # print(n)需要指出的是大部分tf模型的输入layout都是NHWC,而ONNX模型的输入layout为NCHW,因此建议在转换的时候加上
--inputs-as-nchw这个选项,其他选项可以参考文档,非常详细典型的转换命令如下所示:
python3 -m tf2onnx.convert --input xxxx.pb --inputs pb_input:0 --inputs-as-nchw pb_input:0 --outputs resnet_v2_101/predictions/Softmax:0 --output xxxx.onnx注意,由于tensorflow的模型输入一般会比较灵活,输入的batch_size可以留空,可以在运行时传入不同大小的batch_size数据。但是一般在ONNX和TensorRT这些框架中,我们习惯于指定一个固定的batch_size,那如何修改呢,可以参考上一篇文章中我写的那个小工具,有一个例子展示如何修改ONNX模型的batch_size
PyTorch模型转ONNX
在PyTorch推出jit之后,很多情况下我们直接用torch scirpt来做inference会更加方便快捷,并不需要转换成ONNX格式了,当然如果你追求的是极致的效率,想使用TensorRT的话,那么还是建议先转换成ONNX的。
import torch import torchvision dummy_input = torch.randn(10, 3, 224, 224, device='cuda') model = torchvision.models.alexnet(pretrained=True).cuda() input_names = [ "input" ] output_names = [ "output1" ] dynamic_axes = {"input":{0:"batch_size"}, "output1":{0:"batch_size"},} torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names,opset_version=12,dynamic_axes=dynamic_axes)TensorRT7.以后支持动态batch操作,tensorRT7.2.2.3支持opset_version=12,pytorch导出时设置dynamic_axes参数,导出后onnx输入输出变成input[batch_size,3,224,224],output[batch_size,1000]
当然也可以直接修改onnx方式,找到input和output进行修改,一般默认的data是model.graph.input[0],但是如果对graph的data做过删除再添加操作idx就修改了,可以遍历输入查找。
def createGraphMemberMap(graph_member_list): member_map = dict() for n in graph_member_list: member_map[n.name] = n return member_map model = onnx.load_model(onnx_r) graph = model.graph input_map = createGraphMemberMap(model.graph.input) if 'data' in input_map: data_indx = list(input_map).index('data') d = model.graph.input[data_indx].type.tensor_type.shape.dim rate = (input_shape[2] / d[2].dim_value, input_shape[3] / d[3].dim_value) print("rate: ", rate) #d[0].dim_value = input_shape[0] d[0].dim_param = '?' d[2].dim_value = int(d[2].dim_value * rate[0]) d[3].dim_value = int(d[3].dim_value * rate[1]) for output in model.graph.output: d = output.type.tensor_type.shape.dim #d[0].dim_value = input_shape[0] d[0].dim_param = '?' d[2].dim_value = int(d[2].dim_value * rate[0]) d[3].dim_value = int(d[3].dim_value * rate[1]) onnx.save_model(model, args.onnx)第三部分:ONNX到目标平台
ONNX实际只是一套标准,里面只不过存储了网络的拓扑结构和权重(其实每个深度学习框架最后固化的模型都是类似的),脱离开框架是没有办法直接进行inference的。大部分框架(除了tensorflow)基本都做了ONNX模型inference的支持,这里就不进行展开了。
那么如果你想直接使用ONNX模型来做部署的话,有下列几种情况:
第一种情况,目标平台是CUDA或者X86的话,又怕环境配置麻烦采坑,比较推荐使用的是微软的onnxruntime,毕竟是微软亲儿子;
第二种情况,而如果目标平台是CUDA又追求极致的效率的话,可以考虑转换成TensorRT;
第三种情况,如果目标平台是ARM或者其他IoT设备,那么就要考虑使用端侧推理框架了,例如NCNN、MNN和MACE等等。
第一种情况应该是坑最少的一种了,但要注意的是官方的onnxruntime安装包只支持CUDA 10和Python 3,如果是其他环境可能需要自行编译。安装完成之后推理部署的代码可以直接参考官方文档。
第二种情况要稍微麻烦一点,你需要先搭建好TensorRT的环境,然后可以直接使用TensorRT对ONNX模型进行推理;然后更为推荐的做法是将ONNX模型转换为TensorRT的engine文件,这样可以获得最优的性能。关于ONNX parser部分的代码,NVIDIA是开源出来了的(当然也包括其他parser比如caffe的),不过这一块如果你所使用的模型中包括一些比较少见的OP,可能是会存在一些坑;好在NVIDIA有一个论坛,有什么问题或者bug可以在上面进行反馈,专门有NVIDIA的工程师在上面解决大家的问题,不过从我两次反馈bug的响应速度来看NVIDIA还是把TensorRT开源最好,这样方便大家自己去定位bug
第三种情况的话一般问题也不大,由于是在端上执行,计算力有限,所以确保你的模型是经过精简和剪枝过的能够适配移动端的。几个端侧推理框架的性能到底如何并没有定论,由于大家都是手写汇编优化,以卷积为例,有的框架针对不同尺寸的卷积都各写了一种汇编实现,因此不同的模型、不同的端侧推理框架,不同的ARM芯片都有可能导致推理的性能有好有坏,这都是正常情况。