SSD
论文:SSD-Single Shot MultiBox Detector
主要贡献
除了YOLO系列,SSD也算是one-stage目标检测算法的先行者了,相比于YOLOV1和FasterRCNN,其主要特点是:
(1) 在one-stage算法中引入了多尺度预测(主要是为了克服CNN不具有尺度不变性问题)
(2) 参考FasterRCNN中anchor的概念,将其引入one-stage中,通过在每个特征图位置设置不同个数、不同大小和不同比例的anchor box来实现快速收敛和优异性能
(3) 采用了大量有效的数据增强操作
(4) 从当时角度来看,速度和性能都超越当时流行的YOLOV1和FasterRCNN
即使到目前为止,多尺度预测加上anchor辅助思想依然是主流做法。
网络结构
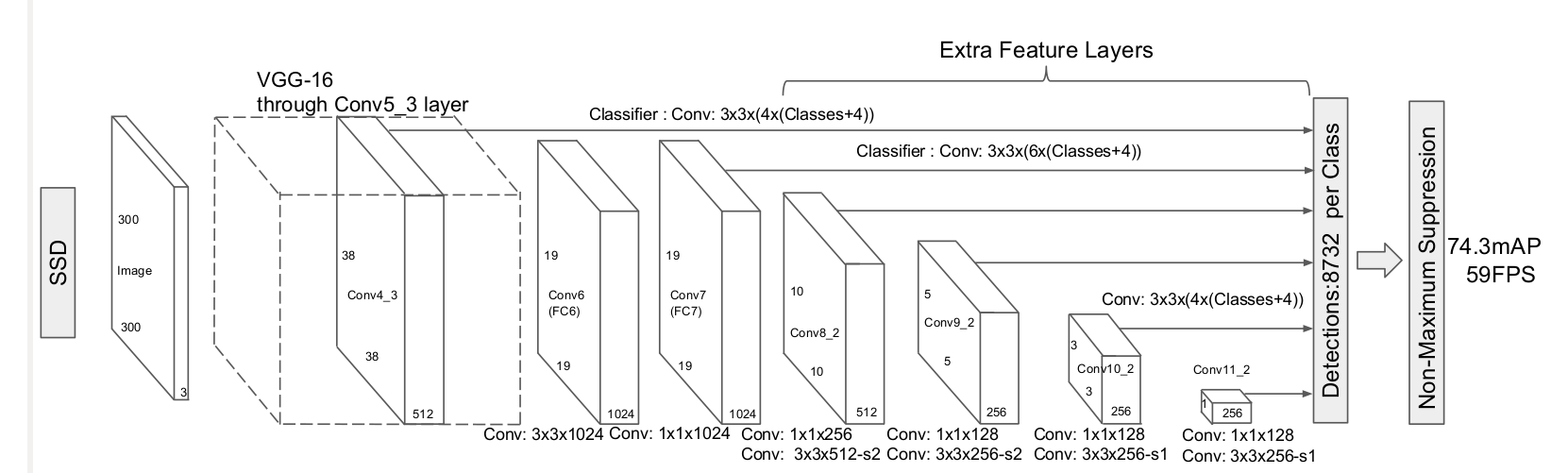
主要 (1)多尺度预测; (2)引入了anchor;(3) 全卷积形式,按照目标检测通用算法流程思路来讲解。ssd也是包括backbone、head、正负样本定义、bbox编解码和loss设计5个部分。
backbone
SSD的骨架是VGG16,其是当前主流的分类网络,其主要特点是全部采用3x3的卷积核,然后通过多个卷积层和最大池化层堆叠而成,是典型的直筒结构。
假设是SSD300,那么一共包括6个输出特征图,分别命名为conv4_3、conv7、conv8_2、conv9_2、conv10_2和conv11_2,其wh大小分别是38x38、19x19、10x10、5x5、3x3和1x1,而SSD512包括7个输出特征图,命名论文中没有给出,其wh大小分别是64x64、32x32、16x16、8x8、4x4、2x2、1x1。
需要注意的是:作者实验发现,conv4_3层特征图比较靠前,其L2范数值(平方然后开根号)相比其余输出特征图层比较大,也就是数值不平衡,为了更好收敛,作者对conv4_3+relu后的输出特征图进行l2 norm到设置的初始20范围内操作,并且将20这个数作为初始值,然后设置为可学习参数。
head
backbone模块会输出n个不同尺度的特征图,head模块对每个特征图进行处理,输出两条分支:分类和回归分支。假设某一层的anchor个数是m,那么其分类分支输出shape=(b,(num_cls+1)×m,h’,w’),回归分支输出shape=(b,4*m,h’,w’)。
正负样本定义
在说明正负样本定义前,由于SSD也是基于anchor变换回归的,而且其有一套自己根据经验设定的anchor生成规则,故需要先说明anchor生成过程。
就是对输出特征图上面任何一点,都铺设指定数目,但是不同大小、比例的先验框anchor。
对于任何一个尺度的预测分支,理论上anchor设置的越多,召回率越高,但是速度越慢。为了速度和精度的平衡,作者在不同层设置了不同大小、不同个数、不同比例的anchor,下面进行详细分析。
以SSD300为例,其提出了一个公式进行设计:
\[s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1),k\in[1,m]\]公式的含义是:输出特征图从大到小,其anchor尺寸设定遵循线性递增规则:随着特征图大小降低,先验框尺度线性增加,从而实现大特征图检测小物体,小特征图检测大物体效果。这里的m是值特征图个数,例如ssd300为6,ssd512为7。第一层conv43是单独设置,不采用上述公式,$s_k$表示先验框大小相对于图片的base比例,而$s{min}$、$s_{max}$表示比例的最小和最大值,voc数据集默认是0.2和0.9,coco数据集默认是0.15和0.9。
(1) 先算出每个输出特征图上anchor的最大和最小尺度 第一个输出层单独设置,其min_size=300x10/100=30,max_size=300x20/100=60。 从第二个输出层开始,首先将乘上100并且取整,得到min_ratio和max_ratio,然后计算出step步长为:
int(np.floor(max_ratio - min_ratio) / (num_levels=6 - 2))
最后利用step计算得到每个输出层的min_size和max_size
# 计算第2个输出图和第self.num_levels个特征图anchor的min_size和max_size
for ratio in range(int(min_ratio), int(max_ratio) + 1, step):
min_sizes.append(int(300 * ratio / 100))
max_sizes.append(int(300 * (ratio + step) / 100))
# 第1个输出图单独算min_size和max_size
if self.input_size == 300:
# conv4_3层的anchor单独设置,不采用公式
if basesize_ratio_range[0] == 0.15: # SSD300 COCO
min_sizes.insert(0, int(300 * 7 / 100))
max_sizes.insert(0, int(300 * 15 / 100))
elif basesize_ratio_range[0] == 0.2: # SSD300 VOC
min_sizes.insert(0, int(300 * 10 / 100))
max_sizes.insert(0, int(300 * 20 / 100))
这样就可以得到6个输出图所需要的min_size和min_size数值,注意这是原图尺度。
(2) 计算(0,0)特征图坐标处的anchor尺度和高宽比 首先配置参数为ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),如果某一层的比例是2,那么表示实际高宽比例是[1,1/2,2],如果是3,则表示[1,1/3,3],可以看出如果某一层ratio设置为[2,3],那么实际上比例有[1,2,3,1/2,1/3]共5种比例,而尺度固定为[1., np.sqrt(max_sizes[k] / min_sizes[k])],k为对应的输出层索引。
带目前为止,6个特征图对应的anchor个数为[2x3=6,2x5=10,10,10,6,6],表示各种比例和尺度的乘积。
(3) 利用base值、anchor尺度和高宽比计算得到每层特征图上(0,0)位置的实际anchor值 这个计算就和常规的faster rcnn完全相同了,计算(0,0)点处的实际宽高,然后利用中心偏移值得到所有anchor的xyxy坐标。
(4) 对特征图所有位置计算anchor 直接将特征图上坐标点的每个位置都设置一份和(0,0)坐标除了中心坐标不同其余都相同的anchor即可,也就是将(0,0)特征图位置上面的anchor推广到所有位置坐标上。基于前面的分析,SSD300一共有8732个anchor。
匹配规则如下:
- 对每个gt bbox进行遍历,然后和所有anchor(包括所有输出层)计算iou,找出最大iou对应的anchor,那么该anchor就负责该gt bbox即该anchor是正样本,该策略保证每个gt bbox一定有一个anchor进行匹配
- 对每个anchor进行遍历,然后和所有gt bbox计算iou,找出最大iou值对应的gt bbox,如果最大iou大于正样本阈值0.5,那么该anchor也负责对应的gt bbox,该anchor为正样本。该策略可以为每个gt bbox提供尽可能多的正样本
- 其余没有匹配上的anchor全部是负样本。
bbox编解码
对于任何一个正样本anchor位置,其gt bbox编码方式采用的依然是Faster rcnn里面的变换规则DeltaXYWHBBoxCoder即
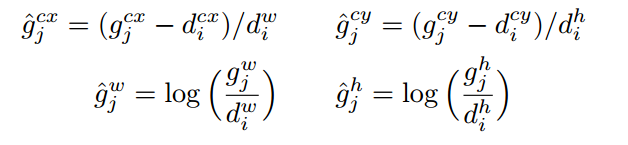
loss设计
对于分类分支来说,其采用的是ce loss,而回归分支采用的是smooth l1 loss,N是所有anchor中正样本anchor的数量,回归分支仅仅计算正样本位置预测值Loss。前面说过经过匹配规则后存在大量负样本和少量正样本,对于分类分支来说这是一个极度不平衡的分类问题,如果不进行任何处理效果可能不太好,故作者采用了在线难负样本挖掘策略ohem,具体是对负样本进行抽样,按照置信度误差或者说负样本分类loss进行降序排列,选取误差较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
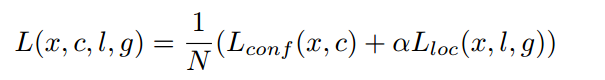
推理流程
(1) 对输入图片进行前处理,变成指定大小输入到网络中,输出8732个基于anchor的预测值,其中任何一个都包括分类长度为num_class+1的向量,和回归长度为4的向量 (2) 首先对分类分支取出预测类别和对应的预测分值,过滤掉低于score_thr阈值的预测值 (3) 对剩下的anchor利用回归分支预测值进行bbox解码,得到实际预测bbox值 (4) 对所有bbox按照类别进行nms操作,得到最终预测bbox和类别信息