Retinanet
RetinaNet算法源自2018年Facebook AI Research的论文 Focal Loss for Dense Object Detection。
主要贡献
(1) 深入分析了何种原因导致one-stage检测器精度低于two-stage检测器 。
(2) 针对上述问题,提出了一种简单但是极其实用的Focal Loss焦点损失函数用于解决类别不平衡、挖掘难分样本,并且focal思想可以推广到其他领域 。
(3) 针对目标检测特定问题,专门设计了一个RetinaNet网络,结合Focal Loss使得one-stage 检测器在精度上能够达到乃至超过two-stage检测器,在速度上和一阶段相同。
网络结构
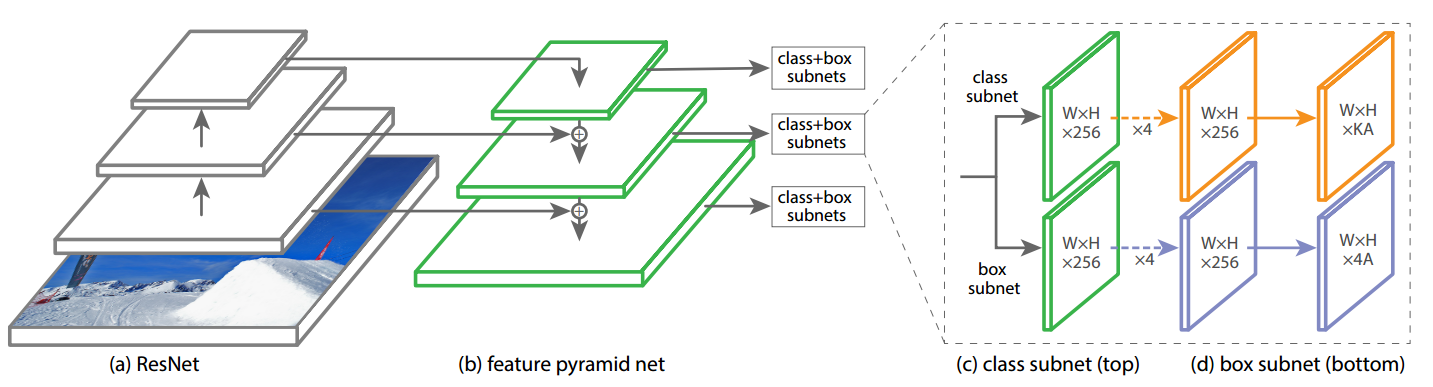
retinanet非常经典,包括骨架resnet+FPN层+输出head,一共包括5个多尺度输出层。
backbone
resnet输出是4个特征图,按照特征图从大到小排列,分别是c2 c3 c4 c5,stride=4,8,16,32。Retinanet考虑计算量仅仅用了c3 c4 c5。
neck
neck模块是标准的FPN结构,其作用是特征融合,其细节是:先对这c3 c4 c5三层进行1x1改变通道,全部输出256个通道;然后经过从高层到底层的最近邻2x上采样+add操作进行特征融合,最后对每个层进行3x3的卷积,得到p3,p4,p5特征图。
还需要构建两个额外的输出层stride=64,128,首先对c5进行3x3卷积且stride=2进行下采样得到P6,然后对P6进行同样的3x3卷积且stride=2,得到P7。
整个FPN层都不含BN和relu
head
retinanet的head模块比较大,其输出头包括分类和检测head两个分支,且每个分支都包括4个卷积层,不进行参数共享,分类head输出通道是num_class * K,检测head输出通道是4 * K,K是anchor个数。虽然每个head的分类和回归分支权重不共享,但是5个输出特征图的head是权重共享的。
正负样本定义
retinanet采用了密集anchor设定规则,每个输出特征图位置都输出K=9个anchor,非常密集。
匹配策略非常简单就是MaxIoUAssigner,大意是:
- 初始所有anchor都定义为忽略样本 。
- 遍历所有anchor,每个anchor和所有gt的最大iou小于0.4,则该anchor是背景 。
- 遍历所有anchor,每个anchor和所有gt的最大iou大于0.5,则该anchor是正样本且最大iou对应的gt是匹配对象 。
- 遍历所有gt,每个gt和所有anchor的最大iou大于0,则该对应的anchor也是正样本,负责对于gt的匹配,可以发现min_pos_iou=0 表示每个gt都一定有anchor匹配,且会出现忽略样本,可能引入低质量anchor。
anchor_generator=dict(
type='AnchorGenerator',
# 每层特征图的base anchor scale,如果变大,则整体anchor都会放大
octave_base_scale=4,
# 每层有3个尺度 2**0 2**(1/3) 2**(2/3)
scales_per_octave=3,
# 每层的anchor有3种长宽比 故每一层每个位置有9个anchor
ratios=[0.5, 1.0, 2.0],
# 每个特征图层输出stride,故anchor范围是4x8=32,4x128x2**(2/3)=812.7
strides=[8, 16, 32, 64, 128]),
每个尺度的anchor计算方法
\[base\_scale=4\\ base\_size=[8,16,32,64,128]\\ scales=[2^0,2^{1/3},2^{2/3}]*base\_scale\\ ratios=[1/2,1,2]\\ h\_ratios=\sqrt{ratios}\\ w\_ratios=1/\sqrt{ratios}\\ hs=base\_size[i]*h\_ratios*scale\\ ws=base\_size[i]*w\_ratios*scale\\ base\_anchors = [\\x\_center - 0.5 * ws, y\_center - 0.5 * hs,\\ x\_center + 0.5 * ws,y\_center + 0.5 * hs]\]#双阈值策略
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
bbox编解码
为了使得各分支Loss更加稳定,需要对gt bbox进行编解码,其编解码过程也是基于gt bbox和anchor box的中心偏移+宽高比规则DeltaXYWHBBoxCoder大意是:
- 特征图每个位置生成9个anchor与gt计算iou,经过阈值筛选得到匹配的anchor以及对应的gt。
- 将匹配anchor与对应gt转换成中心及宽高形式,计算$dx,dy,dw,dh$。
dx = (gx - px) / pw
dy = (gy - py) / ph
dw = torch.log(gw / pw)
dh = torch.log(gh / ph)
loss计算
虽然正负样本定义阶段存在极度不平衡,但是由于focal loss的引入可以在很大程度克服。故分类分支采用focal loss,回归分支可以采用l1 loss或者smooth l1 loss,实验效果表明l1 loss好一些。
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)))
Focal Loss
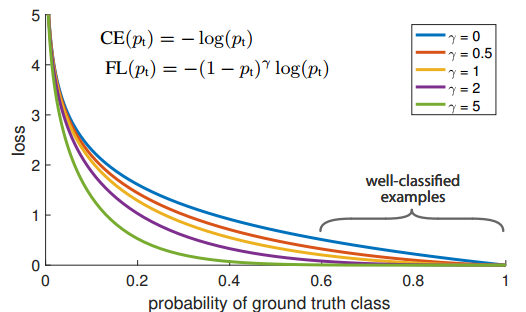
FL本质上解决的是将大量易学习样本的loss权重降低,但是不丢弃样本,突出难学习样本的loss权重,但是因为大部分易学习样本都是负样本,所以还有一个附加功能即解决了正负样本不平衡问题。其是根据交叉熵改进而来,本质是dynamically scaled cross entropy loss,直接按照loss decay掉那些easy example的权重,这样使训练更加bias到更有意义的样本中去,说通俗点就是一个解决分类问题中类别不平衡、分类难度差异的一个loss。
注意上面的公式表示label必须是one-hot形式。只看图示就很好理解了,对于任何一个类别的样本,本质上是希望学习的概率为1,当预测输出接近1时候,该样本loss权重是很低的,当预测的结果越接近0,该样本loss权重就越高。而且相比于原始的CE,这种差距会进一步拉开。由于大量样本都是属于well-classified examples,故这部分样本的loss全部都需要往下拉。 \(FL=-\alpha_t(1-p_t)^\gamma log(p_t)\)
bias初始化
在Retinanet中,其分类分支初始化bias权重设置非常关键。$b=-\log(\frac{1-\pi}{\pi}),\pi=0.01$,这个操作非常关键,原因是anchor太多,负样本远远大于正样本,也就是说分类分支,假设负样本:正样本数=1000:1。分类是sigmod输出,其输出的负数表示负样本label,如果某个batch的分类输出都是负数,那么也就是预测全部是负类,这样算loss时候就会比较小,相当于强制输出的值偏向负类。许多anchor free方法也是用的改进的高斯FL,所以也是用的BCE。
推理流程
在推理阶段,对5个输出head的预测首先取topK的预测值,然后用0.05的阈值过滤掉背景,此时得到的检测结果已经大大降低,此时再对检测结果的box分支进行解码,最后把输出head的检测结果拼接在一起,通过IoU=0.5的NMS过滤重叠框就得到最终结果。