Cornernet
论文:CornerNet: Detecting Objects as Paired Keypoints,ECCV2018
代码链接:https://github.com/umich-vl/CornerNet
主要贡献
1、将目标检测问题当作关键点检测问题来解决,也就是通过检测目标框的左上角和右下角两个关键点得到预测框,没有anchor的概念。
2、整个检测网络的训练是从头开始的,并不基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。
常用的目标检测算法都是基于anchor的,但是引入anchor的缺点在于:1、正负样本不均衡。大部分检测算法的anchor数量都成千上万,但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及focal loss等算法来解决这个问题。2、引入更多的超参数,比如anchor的数量、大小和宽高比等。
网络结构
backbone
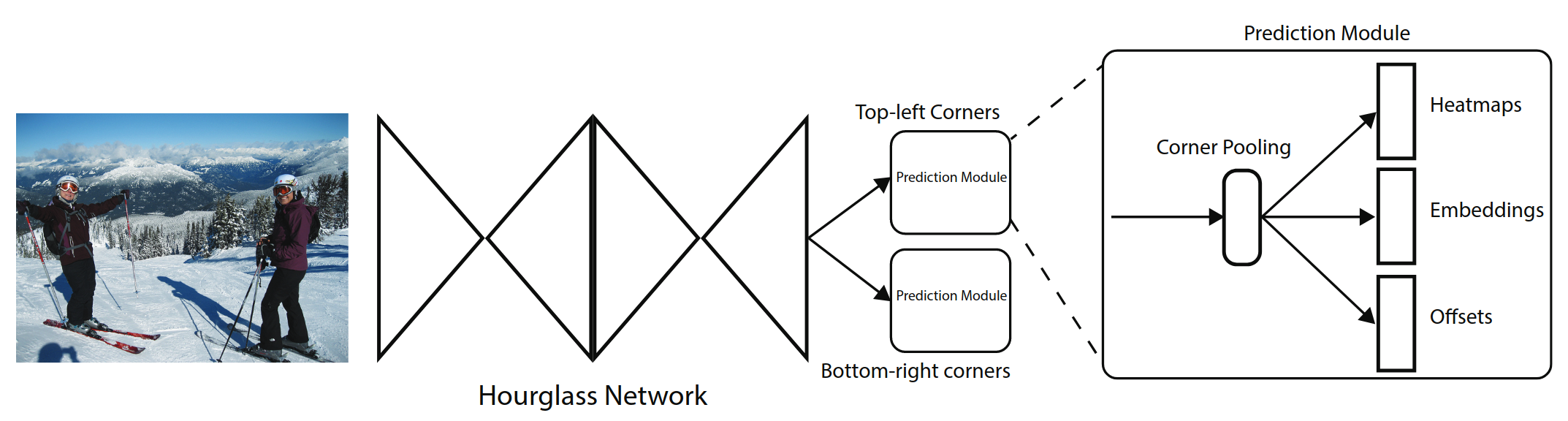
CornerNet 的基础网络结构采用hourglass类型的网络模块,连续堆叠了2个这样的模块。hourglass结构可以很好的结合局部特征和全局特征。在hourglass模块中没有使用pooling操作,而是使用stride=2的卷积实现下采样,这也可以获得更快的速度。最终feature map被缩小5倍。其中卷积层的通道数分别为(256; 384; 384; 384; 512)。hourglass结构的网络深度为104层。
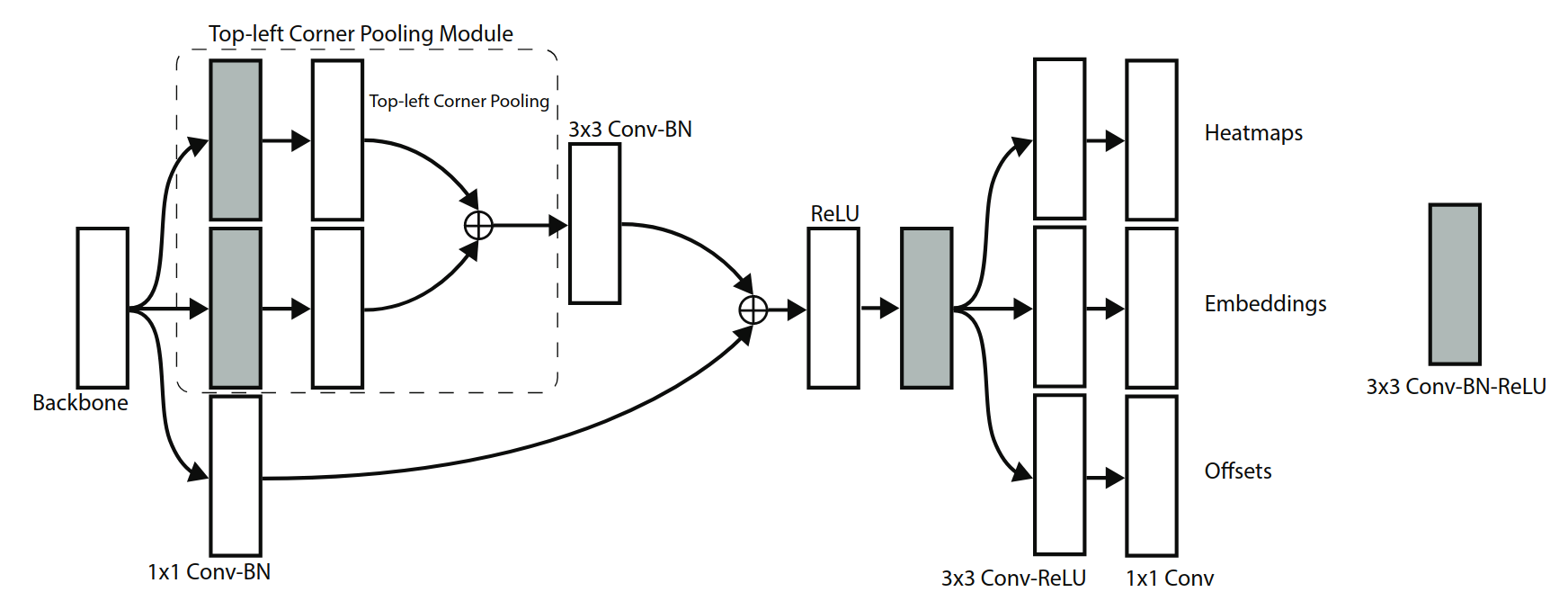
CornerNet 的检测模块如上图所示。上图只表示了top-left部分的结构,bottom-right也有类似的结构。经过backbone之后,首先经过corner pooling操作,输出pooling后的特征图,然后再和backbone的特征图做融合。相当于resnet中的shortcut结构在这里使用corner pooling替换。最终分为3个分支,分别输出heatmap,Embedding,offsets。网络最终top-left和bottom-right各输出一个heatmap为80x128x128、嵌入向量Embedding为1x128x128、偏移offsets为2x128x128。
传统的检测框架边框的位置是通过(x,y,width,height)确定的。而CornerNet的heatmap既包含边框的分数,还包含边框的位置。由于网络不断下采样会造成最终的坐标和原始图像的有偏移,这里采用了回归的offsets解决。至于左上角的点和右下角的点的配对,使用embedding来解决。
根据mmdetection上结构绘制网络结构图,hourglass有5层,hourglass两个输出均为256x128x128,共享cornerhead。
Loss计算
\[L=L_{det}+\alpha L_{pull}+\beta L_{push}+\gamma L_{off}\]heatmap部分损失函数:
\[L_{det}=\frac{-1}{N}\sum_{c=1}^{C}\sum_{i=1}^{H}\sum_{j=1}^{W}\left \{ \begin{array}{c} (1-p_{cij})^{\alpha}\log(p_{cij}) & \text{if } y_{cij}=1 \\ (1-y_{cij})^{\beta}(p_{cij})^{\alpha}\log(1-p_{cij}) & \text{otherwise} \end{array} \right.\]heatmap输出预测角点信息,维度为CxHxW,其中C表示目标的类别(没有背景类),这个特征图的每个通道都是一个mask,mask的范围为0到1(输出后经过sigmod),表示该点是角点的分数。$L_{det}$是GaussianFocalLoss是改良版的focal loss,$p_{cij}$表示预测的heatmap在第c个通道(i,j)位置的值,$y_{cij}$表示对应位置的ground truth,N表示目标的数量。$y_{cij}$的时候损失函数就是focal loss,$y_{cij}$为其他值表示该位置不是目标角点,按理为0(大部分算法这样处理的),但这里基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的$y_{cij}$值接近1,这部分通过$\beta$参数控制权重,这是和focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积。

高斯核半径r,为了满足iou>min_overlap,需满足以下条件,最后取min(r1, r2, r3)
Case1:一个角点在gt内部,一个在外部
\[\cfrac{(w-r)*(h-r)}{w*h+(w+h)r-r^2} \ge {iou} \quad\Rightarrow\quad {r^2-(w+h)r+\cfrac{1-iou}{1+iou}*w*h} \ge 0 \\ {a} = 1,\quad{b} = {-(w+h)},\quad{c} = {\cfrac{1-iou}{1+iou}*w*h}\\ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}\]Case2:两个角点都在gt内部
\[\cfrac{(w-2*r)*(h-2*r)}{w*h} \ge {iou} \quad\Rightarrow\quad {4r^2-2(w+h)r+(1-iou)*w*h} \ge 0 \\ {a} = 4,\quad {b} = {-2(w+h)},\quad {c} = {(1-iou)*w*h}\\ {r} \le \cfrac{-b-\sqrt{b^2-4*a*c}}{2*a}\]Case:两个角点都在gt外部
\[\cfrac{w*h}{(w+2*r)*(h+2*r)} \ge {iou} \quad\Rightarrow\quad {4*iou*r^2+2*iou*(w+h)r+(iou-1)*w*h} \le 0 \\ {a} = {4*iou},\quad {b} = {2*iou*(w+h)},\quad {c} = {(iou-1)*w*h} \\ {r} \le \cfrac{-b+\sqrt{b^2-4*a*c}}{2*a}\]2D高斯核函数$e^{-\frac{x^2+y^2}{2\sigma^2}}$,$\sigma$为(2*r+1)/6,叠加中心为角点位置,当两个同类目标交叠时,mask取最大值。
offset部分损失函数:
\[L_{off}=\frac{1}{N}\sum_{k=1}^{N}SmoothL1Loss(o_k,\hat{o_k})\\ o_k=(\frac{x_k}{n}-\left \lfloor \frac{x_k}{n}\right \rfloor,\frac{y_k}{n}-\left \lfloor \frac{y_k}{n}\right \rfloor)\]这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而这里的offset是表示在取整计算时丢失的精度信息。只计算角点位置损失。
embedding部分损失函数:
\[L_{pull}=\frac{1}{N}\sum_{k=1}^{N}[(e_{t_{k}}-e_k)^2+(e_{b_{k}}-e_k)^2]\\ L_{push}=\frac{1}{N(N-1)}\sum_{k=1}^{N}\sum_{j=1\\j\neq k}^{N}max(0,\Delta-\left |e_k-e_j \right |)\]$e_{t_{k}}$表示第k个目标的左上角角点的embedding vector,$e_{b_{k}}$表示第k个目标的右下角角点的embedding vector,$e_{k}$表示$e_{t_{k}}$和$e_{b_{k}}$的均值,$L_{pull}$用来缩小属于同一个目标(第k个目标)的两个角点的embedding vector(etk和ebk)距离,$L_{push}$用来扩大不属于同一个目标的两个角点的embedding vector距离。
Corner pooling
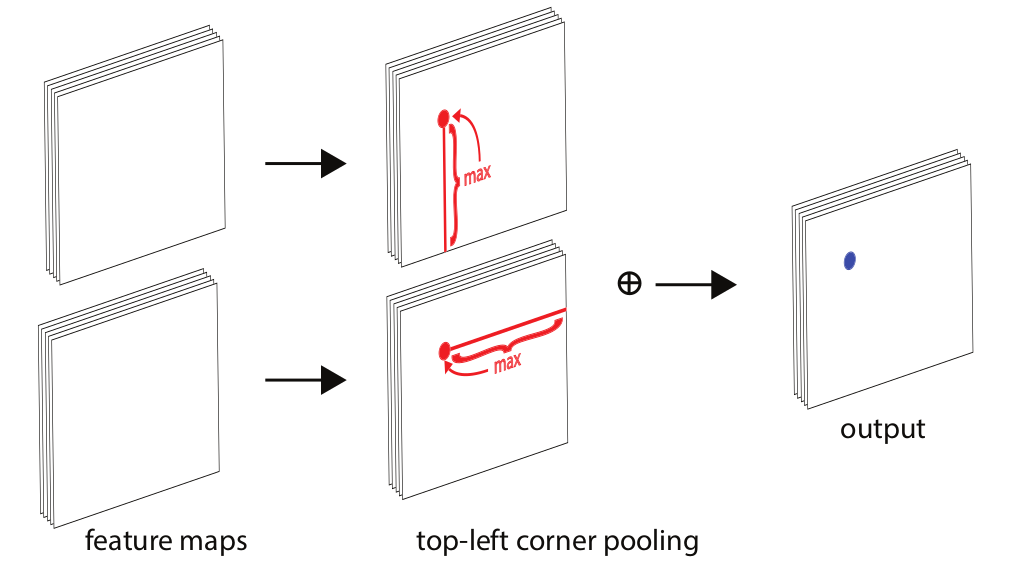
因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息,左上角角点的下边有目标左侧的特征信息,因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。
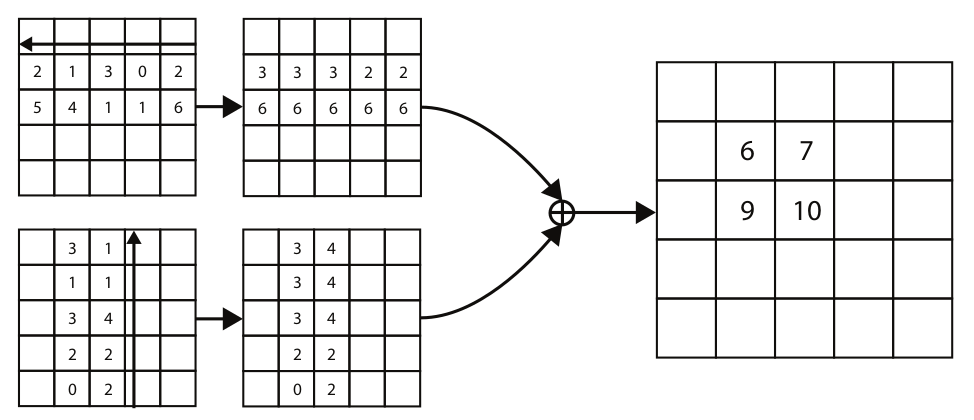
下图是针对左上角点做corner pooling,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是(i,j))做corner pooling,那么就计算(i,j)到(i,H)的最大值;同时计算(i,j)到(W,j)的最大值,然后将这两个最大值相加得到(i,j)点的值。右下角点的corner pooling操作类似,只不过计算最大值变成从(0,j)到(i,j)和从(i,0)到(i,j)。(torch实现torch.cummax+flip)
推理流程
1、在得到预测角点后,会对这些角点做NMS操作,选择前100个左上角角点和100个右下角角点。
2、计算左上角和右下角角点的embedding vector的距离时采用L1范数,距离大于0.5或者两个点来自不同类别的目标的都不能构成一对。
3、测试图像采用0值填充方式得到指定大小作为网络的输入,而不是采用resize,另外同时测试图像的水平翻转图并融合二者的结果。
4、最后通过soft-nms操作去除冗余框,只保留前100个预测框。
优化方向
对box的坐标、尺寸和类别的预测只依赖对象的边缘特征,并没有使用对象内部的特征,这样的话会预测很多False Positive box