ShuffleNetV1
论文名称:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
主要贡献
ShuffleNet是face++在MobileNetV1思想基础上提出的移动端模型。前面说过MobileNetV1主要是通过深度可分离卷积来减少参数和计算量,并且深度可分离卷积实际上包括逐通道分离卷积和1x1标准点卷积两个模块,由于通常输入和输出通道比较大,故MobileNetV1的主要参数和计算量在于第二步的1x1标准逐点卷积
ShuffleNet主要改进是对1x1标准逐点卷积的计算量和参数量进一步缩减,具体是引入了1x1标准逐点分组卷积,但是分组逐点卷积会导致组和组之间信息无法交流,故进一步引入组间信息交换机制即shuffle层。通过上述两个组件,不仅减少了计算复杂度,而且精度有所提升。
算法设计
channel shuffle
当直接对1x1标准逐点卷积进行改进,变成1x1标准逐点分组卷积,通过将卷积运算的特征图限制在每个组内,模型的计算量可以显著下降。然而这样做带来了明显问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换,这将可能影响到模型的表示能力和识别精度。因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制,如下所示:
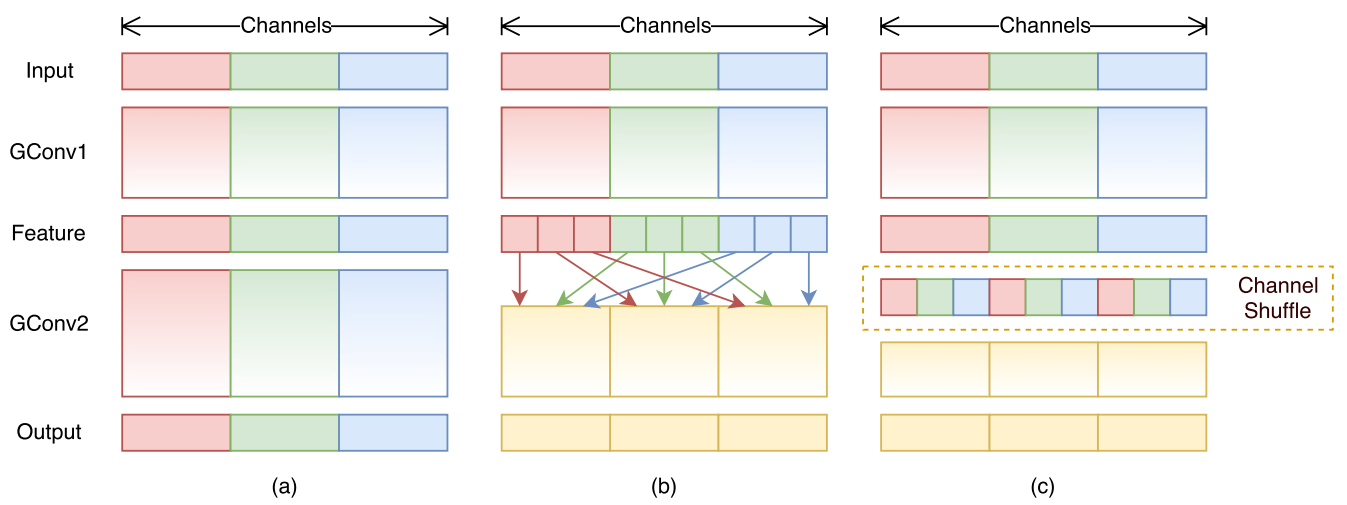
(a)图是堆叠多个分组卷积,组和组之间没有信息流通,这肯定会影响到模型的表示能力和识别精度,故可以在两个分组卷积层直接引入特征图打乱操作,如图(b)所示,而(c)是本文提出的通道shuffle层,效果和(b)等jia,但是实现上更加高效,并且是可导的。
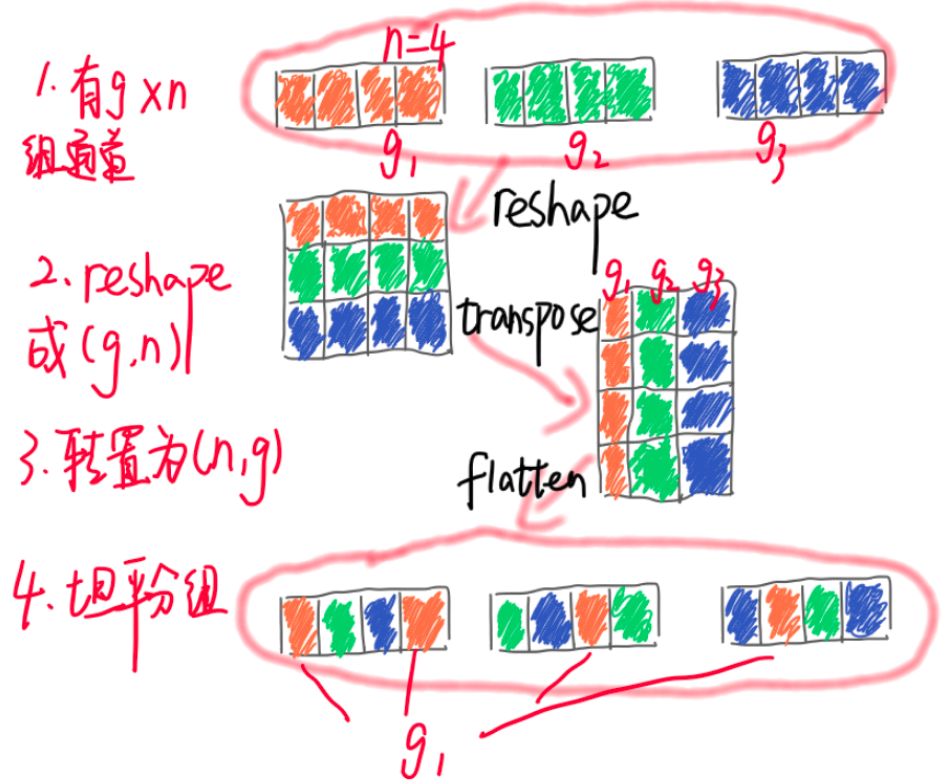
channel shuffle的实现非常简单,示意图如下:
核心就是先对输入特征图按照通道维度进行分组,然后转置,最后变成原始输入尺度即可。
ShuffleNet单元
基于上述所提组件,可以构建基础的shufflenet单元:
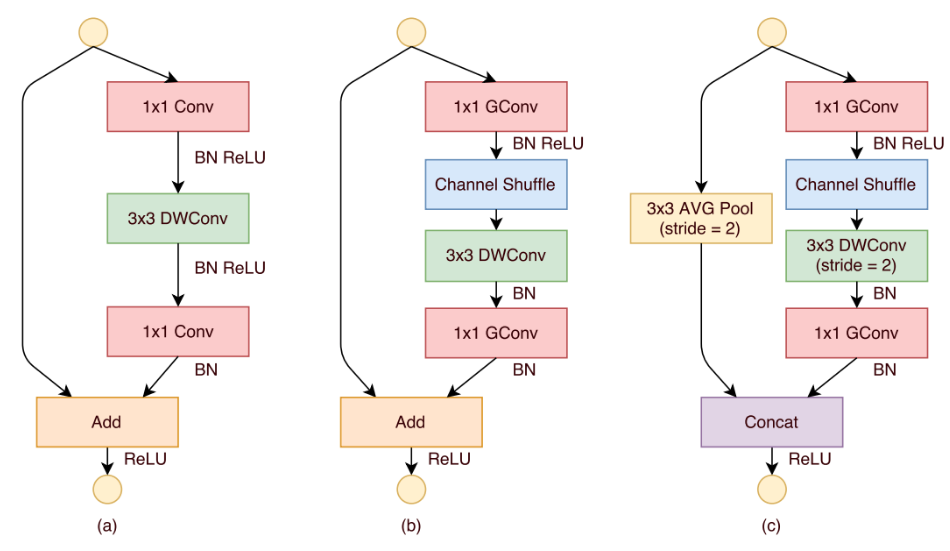
(a)是带有深度可分离卷积的bottleneck单元;(b)是设计的stride=1时候的shuffle单元;(c)是设计的stride=2时候的shuffle单元,在该单元中,使用concat来使得通道加倍,导致信息不缺失。
总结
shufflenetv1好于mobilenetv1,原因是: (1) 引入了残差结构 (2) 用了很多分组卷积,导致在同样FLOPS情况下,通道数可以多一些,模型复杂度比mobilenet低
shufflenet核心改进就是针对1x1逐点分组卷积存在的组内信息无法交互问题而提出了通道shuffle操作,并且通过实验发现在分组数增加情况下,可以显著减低计算复杂度,从而可以通过增加通道来实现比mobilenet精度更高且速度更快的模型功能。由于后续有新提出的shufflenetv2,故shufflenetv1现在用的也比较少。
ShuffleNetV2
论文名称:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
主要贡献
shufflenetv2论文最大贡献不是提出了一个新的模型,而是提出了4条设计高效CNN的规则,该4条规则考虑的映射比较多,不仅仅FLOPS参数,还可以到内存使用量、不同平台差异和速度指标等等,非常全面。在不违背这4条规则的前提下进行改进有望设计出速度和精度平衡的高效模型。
算法核心
到目前为止,前人所提轻量级CNN框架取得了很好效果,例如Xception、MobileNet、MobileNetV2和ShuffleNetv1等,主要采用技术手段是分组卷积Group convolution和逐深度方向卷积depthwise convolution。
在上述算法中,除了精度要求外,评价模型复杂度都是采用FLOPs指标(每秒浮点加乘运算次数),在mobilnetv1、v2和ShuffleNet都是采用该指标的。然而FLOPs 其实是一种间接指标,它只是真正关心的直接指标(如速度或延迟)的一种近似形式,通常无法与直接指标划等号。先前研究已对这种差异有所察觉,比如MobileNet V2要远快于 NASNET-A(自动搜索出的神经网络),但是两者FLOPs相当,它表明FLOPs近似的网络也会有不同的速度。所以,将FLOPs作为衡量计算复杂度的唯一标准是不够的,这样会导致次优设计。
研究者注意到FLOPs仅和卷积部分相关,尽管这一部分需要消耗大部分的时间,但其它过程例如数据 I/O、数据重排和元素级运算(张量加法、ReLU 等)也需要消耗一定程度的时间。
间接指标(FLOPs)和直接指标(速度)之间存在差异的原因可以归结为两点:
- 对速度有较大影响的几个重要因素对FLOPs不产生太大作用,例如内存访问成本 (MAC)。在某些操作(如组卷积)中,MAC占运行时间的很大一部分,对于像GPU这样具备强大计算能力的设备而言,这就是瓶颈,在网络架构设计过程中,内存访问成本不能被简单忽视
- 并行度。当FLOPs相同时,高并行度的模型可能比低并行度的模型快得多
其次,FLOPs相同的运算可能有着不同的运行时间,这取决于平台。例如,早期研究广泛使用张量分解来加速矩阵相乘。但是,近期研究发现张量分解在GPU上甚至更慢,尽管它减少了75%的 FLOPs。本文研究人员对此进行了调查,发现原因在于最近的 CUDNN库专为3×3 卷积优化:当然不能简单地认为3×3卷积的速度是1×1卷积速度的1/9。
总结如下就是:
- 影响模型运行速度还有别的指标,例如MAC(memory access ),并行度(degree of parallelism)
- 不同平台有不同的加速算法,这导致flops相同的运算可能需要不同的运算时间。
据此,提出了高效网络架构设计应该考虑的两个基本原则:第一,应该用直接指标(例如速度)替换间接指标(例如 FLOPs);第二,这些指标应该在目标平台上进行评估。在这项研究中,作者遵循这两个原则,并提出了一种更加高效的网络架构。
4条高效网络设计原则
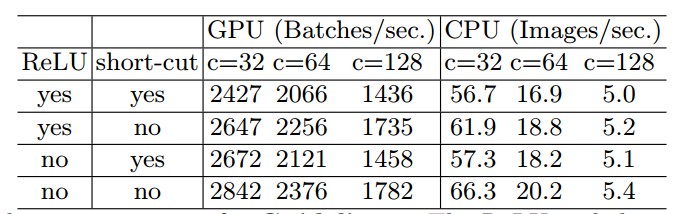
G1. 相同的通道宽度可最小化内存访问成本(MAC) 假设内存足够大一次性可存储所有特征图和参数;卷积核大小为1 * 1 ;输入通道有c1个;输出通道有c2个;特征图分辨率为h * w,则在1x1的卷积上,FLOPS:$B=hwc1c2$,MAC:$hw(c1+c2)+c1c2$,容易推出: \(MAC>2\sqrt{hwB}+\frac{B}{hw}\) MAC是内存访问量,hwc1是输入特征图内存大小,hwc2是输出特征图内存大小,c1xc2是卷积核内存大小。从公式中我们可以得出MAC的一个下界,即当c1==c2 时,MAC取得最小值。以上是理论证明,下面是实验证明:
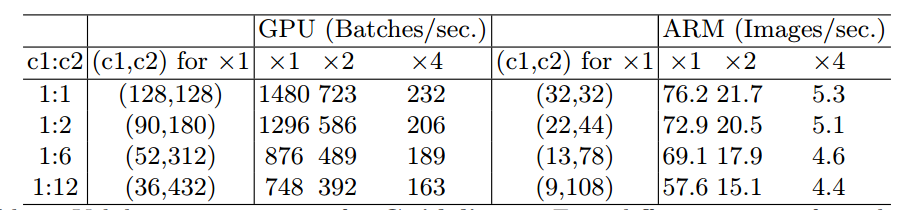
可以看出,当c1==c2时,无论在GPU平台还是ARM平台,均获得了最快的runtime。
G2. 过度使用组卷积会增加MAC 和(1)假设一样,设g表示分组数,则有: \(MAC=hw(c_1+c_2)+\frac{c_1c_2}{g}\\ =hwc_1+\frac{Bg}{c_1}+\frac{B}{hw}\) 其中$B=hwc_1c_2$,当固定c1 w h和B,增加分组g,MAC也会增加,证明了上述说法。其中c1 w h固定,g增加的同时B复杂度也要固定,则需要把输出通道c2增加,因为g增加,复杂度是要下降的。以上是理论证明,下面是实验证明:
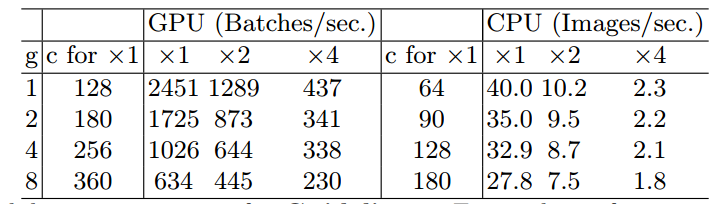
可以看出,g增加,runtime减少。
G3. 网络碎片化(例如 GoogLeNet 的多路径结构)会降低并行度 理论上,网络的碎片化虽然能给网络的accuracy带来帮助,但是在平行计算平台(如GPU)中,网络的碎片化会引起并行度的降低,最终增加runtime,同样的该文用实验验证:
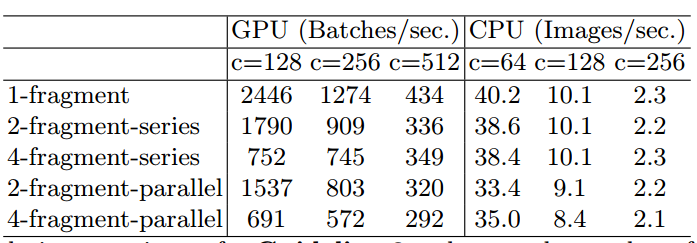
可以看出,碎片化越多,runtime越大。
G4. 元素级运算不可忽视
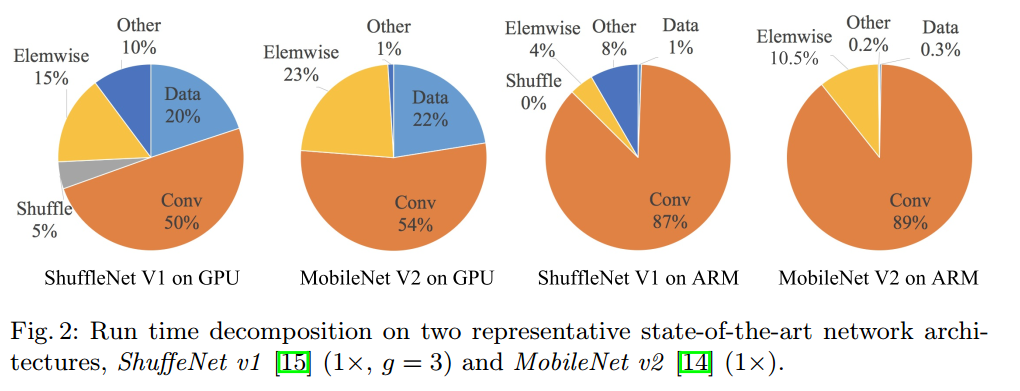
element-wise operations也占了不少runtime,尤其是GPU平台下,高达15%。ReLU、AddTensor及AddBias等这一类的操作就属于element-wise operations. 这一类操作,虽然flops很低,但是MAC很大,因而也占据相当时间。同样地,通过实验分析element-wise operations越少的网络,其速度越快。
以上就是作者提出的4点设计要求,总结如下
- 1x1卷积进行平衡输入和输出的通道大小
- 组卷积要谨慎使用,注意分组数
- 避免网络的碎片化
- 减少元素级运算
结合上述4点可以对目前移动端网络进行分析:
- ShuffleNetV1严重依赖组卷积(违反G2)和瓶颈形态的构造块(违反 G1)
- MobileNetV2使用倒置的瓶颈结构(违反G1),并且在“厚”特征图上使用了深度卷积和 ReLU激活函数(违反了G4)
- 自动生成结构的碎片化程度很高,违反了G3
算法模型
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。
基于以上缺点,作者重新设计了v2版本。V2主要结构是多个blocks堆叠构成,block又分为两种,一种是带通道分离的Channel Spilit,一种是带Stride=2。图示如下:
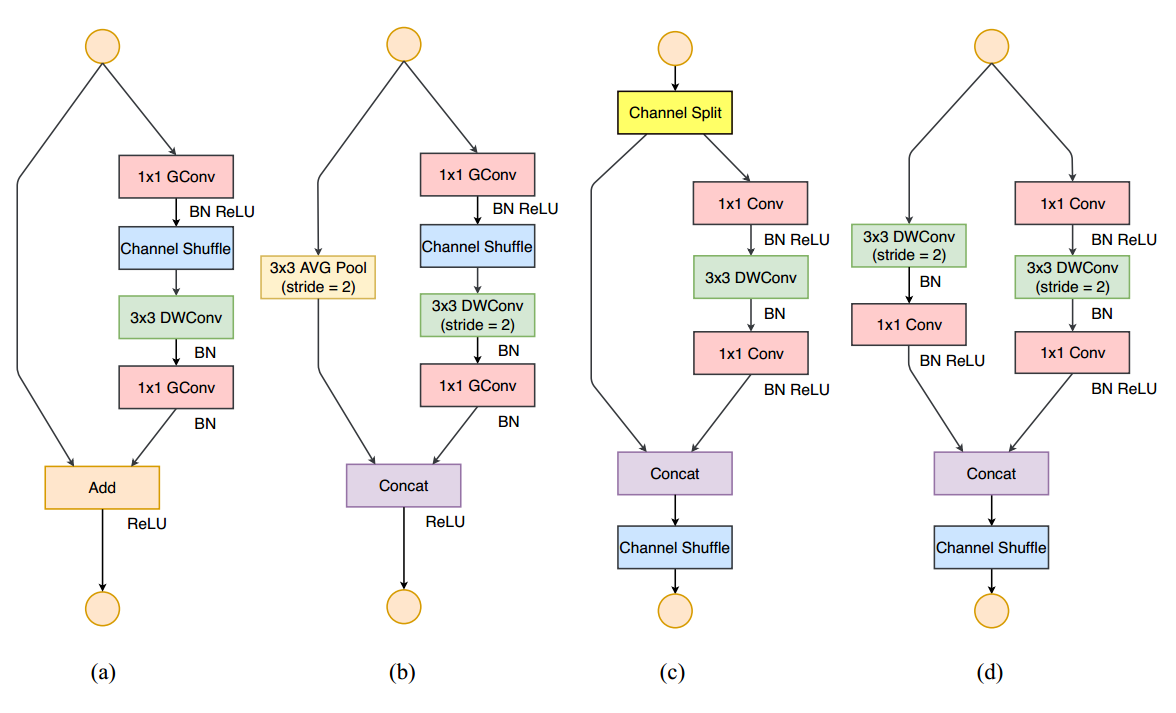
(a)为v1中的stride=1的block,(b)为v1中的stride=2的block,(c)是新设计的v2中的stride=1的block,(d)是新设计的v2中的stride=2的block。
在每个单元开始,c 特征通道的输入被分为两支,分别占据c−c’和c’个通道(一般设置c=c’*2)。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于stride=2的模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
总结
shufflenetv2针对目前移动端模型都仅仅考虑精度和FLOPS参数,但是这两个参数无法直接反映真正高效网络推理要求,故作者提出了4条高效网络设计准则,全面考虑了各种能够影响速度和内存访问量的因素,并给出了设计规则。再此基础上设计了shufflenetv2,实验结果表明速度和精度更加优异。