MobileNetV1
论文名称:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
主要贡献
提出的深度可分离卷积(depthwise separable convolutions)操作是现在移动端压缩模型的基本组件,在此基础上通过引入宽度因子(width multiplier)和分辨率因子(resolution multiplier)来构建不同大小的模型以适应不同场景精度要求。
算法核心
论文指出常用的模型小型化手段有: (1) 卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核,例如分数Inception结构 (2) 使用bottleneck结构即大量使用1x1卷积,以SqueezeNet为代表 (3) 以低精度浮点数保存,例如Deep Compression (4) 冗余卷积核剪枝及哈弗曼编码
首先需要明确移动端模型的要求是:在不会大幅降低模型精度的前提下,最大程度的提高运算速度。常规能够想到的做法是:
- 减少模型参数量
- 减少网络计算量
模型参数量少意味着整个模型的size比较小,非常适合移动端,试想用户下载个简单的图像分类功能app都超过100Mb,那肯定无法接受,而减少网络计算量可以使得在cpu性能有限的手机上流畅运行。
针对上述两个需求,mobilenetv1提出了两个创新:
- 轻量级移动端卷积神经网络。充分利用深度可分离卷积,其本质是冗余信息更少的稀疏化表达,在性能可接受前提下有效减少网络参数
- 进一步引入两个简单超参来平衡网络延时和精度,可以针对不同的应用场景进行有效裁剪
深度可分离卷积
首先分析常规卷积流程,然后再引入深度可分离卷积。
(1) 常规卷积
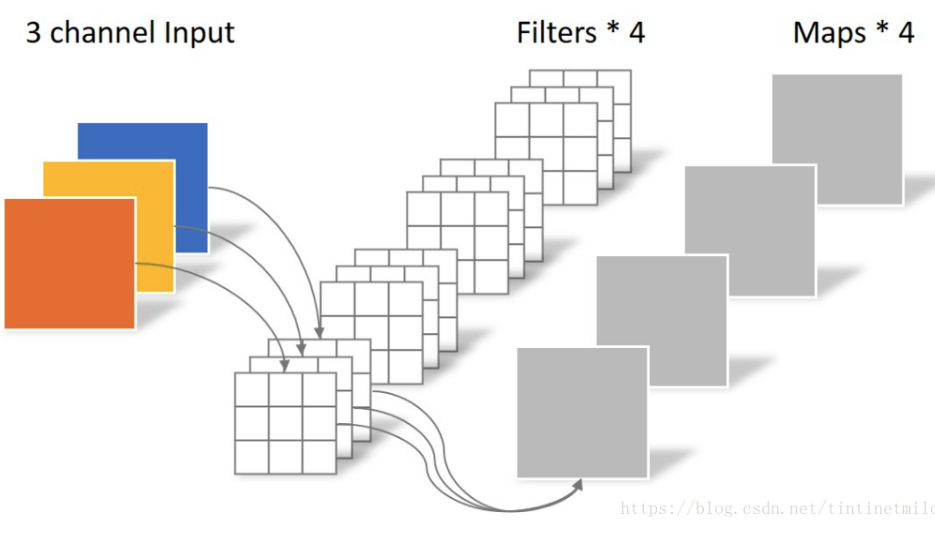
设输入特征图维度是$D_FD_FM$,$D_F$是特征图宽,并且宽和高相等,假设输出的特征图宽高和输入一致,仅仅通道数更改为,那么常规卷积的操作为:首先将N个K×K的卷积核分别作用在M个输入通道上,产生M×N个特征图,然后叠加每个输入通道对应的特征图,最终得到N个通道的输出特征图。
以上面图示为例,不考虑batch和padding,假设卷积核参数是3x5x5x4(3是输入通道,4是输出通道,5x5是kernel),输入特征图shape是(3,100,100),输出特征图shape是(4,100,100),则计算过程是:将滤波器参数3x5x5x4分成4组即[3x5x5,3x5x5,3x5x5,3x5x5],然后将4组滤波器(3,5,5)和同一个输入特征图(3,100,100)分别进行卷积操作(对于每一层滑动窗口内计算都是先对应位置相乘,然后全部加起来变成1个数输出),输出也是4组特征图[1x100x100,1x100x100,1x100x100,1x100x100],然后concat最终就得到输出特征图shape为(4,100,100)。
上述卷积操作参数量比较简单是$MKKN$,而计算量(乘加次数)是$MD_FD_FNKK$,这里是把一次先乘后加的操作合并了。
(2) 深度可分离卷积 深度可分离卷积实际是两次卷积操作,分别是depthwise convolution和pointwise convolution。对每个通道(深度)分别进行空间卷积(depthwise convolution),并对输出进行拼接,随后使用1x1卷积核或者说逐点进行通道卷积(pointwise convolution)以得到特征图。
依然以上面的例子为例进行分析,卷积核参数是3x5x5x4(3是输入通道,4是输出通道,5x5是kernel),输入特征图shape是(3,100,100),输出特征图shape是(4,100,100)。
第一步: depthwise convolution
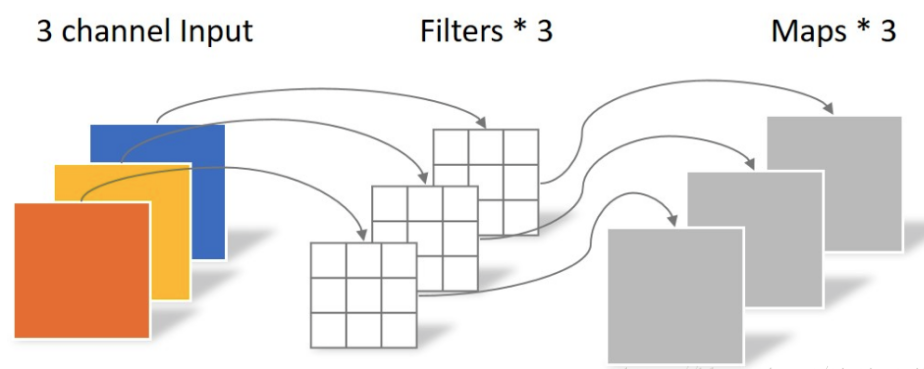
该部分的卷积参数是3x5x5x1,具体计算过程是:将滤波器参数3x5x5x1分成3组即[5x5x1,5x5x1,5x5x1], 同时将输入特征图也分成三组即[100x100x1,100x100x1,100x100x1],然后将3组滤波器(5,5,1)和3组特征图100x100x1进行一一对应的计算卷积操作,输出三组即[100x100x1,100x100x1,100x100x1],concat后输出是3x100x100。
可以看出其参数量是$MKK$,而计算量(乘加次数)是$MD_FD_FKK$。
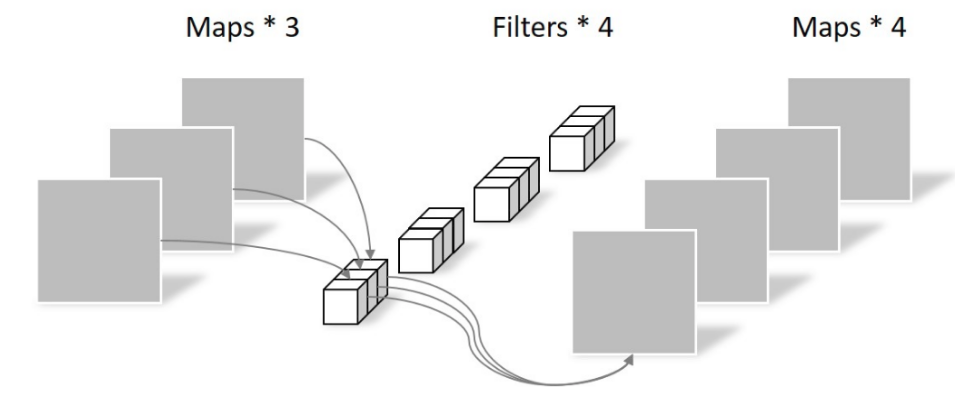
这步骤其实是标准卷积,只不过kernel比较特殊是1x1的。故其卷积操作参数量比较简单是$MN$,而计算量(乘加次数)是$MD_FD_FN$。
故深度可分离卷积的总参数量是$MKK+MN$,计算量是$MD_FD_FKK+MD_FD_FN$
对比常规卷积计算量是:
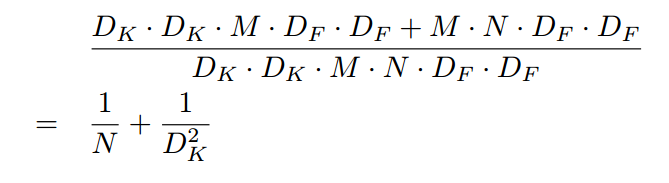
分子是通道可分离卷积计算量,分母是常规卷积计算量。可以看出,如果取3,那么理论上可以加速8到9倍,当然参数量也要显著下降。
通过对卷积进行分步改进,则将标准的conv+bn+relu变成了如下所示:
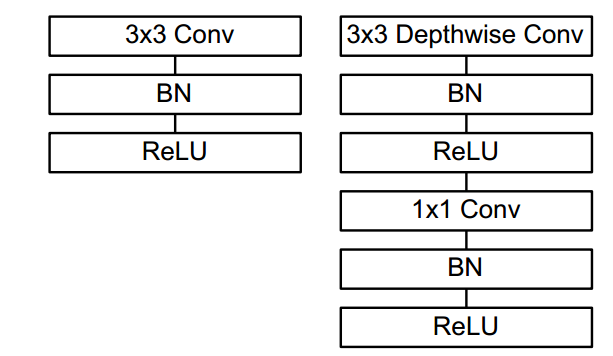
实现比较巧妙,通过分组卷积(分组数正好等于输入通道数)就可以实现深度可分离卷积,后面再接一个普通的1x1卷积即可。
宽度因子和分辨率因子
作者指出,尽管上述MobileNet在计算量和模型尺寸方面具备很明显的优势,但是在一些对运行速度或内存有极端要求的场合,还需要更小更快的模型,如何能够在不重新设计模型的情况下,以最小的改动就可以获得更小更快的模型呢?故本文提出的宽度因子和分辨率因子就是解决上述问题的配置参数。
宽度因子$\alpha$是一个属于(0,1]之间的数,常用配置为{1,0.75,0.5,0.25},附加于网络的通道数上,使得整个mobilenet模型的计算量和参数数量约减到$\alpha$的平方倍,计算量如下:
$D_kD_k\alpha MD_FD_F+\alpha M\alpha N *D_FD_F$
分辨率因子$\beta$的取值范围在(0,1]之间,是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合宽度因子,计算量如下:
$D_kD_k\alpha M\beta D_F\beta D_F+\alpha M\alpha N *\beta D_F\beta D_F$
$\beta=1$就是标准的mobilenet,$\beta<1$会对输入进行缩减,常见的网络输入是{224, 192, 160,128},通过参数$\beta$可以非常有效的将计算量和参数数量约减到$\beta$的平方倍。
训练细节
作者基于TensorFlow训练MobileNet,使用RMSprop算法优化网络参数。考虑到较小的网络不会有严重的过拟合问题,因此没有做大量的数据增强工作。在训练过程中也没有采用训练大网络时的一些常用手段,例如:辅助损失函数,随机图像裁剪输入等。而且depthwise卷积核含有的参数较少,作者发现这部分最好使用较小的weight decay或者不使用weightdecay。
总结
本文核心是提出了深度可分离卷积操作,可以在仅仅牺牲一点点参数量的基础上显著减少参数量和计算量,同时为了能够适用不同资源的移动设备,还引入了宽度因子和分辨率因子来复合缩放基础mobilenet。
MobileNetV2
论文题目:MobileNetV2: Inverted Residuals and Linear Bottlenecks
主要贡献
提出线性瓶颈层Linear Bottlenecks,也就是去掉了1x1降维输出层后面的非线性激活层,目的是为了保证模型的表达能力
提出反转残差块Inverted Residual block,该结构和传统residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map
简单来说,mobilenetv2是基于mobilenetv1的通道可分离卷积优势,然后再加入了残差模块功能,最后通过理论分析和实验证明,对残差模块进行了一定程度的修改,使其在移动端发挥最大性能。
算法核心
mobilenetV1主要是引入了depthwise separable convolution代替传统的卷积操作,实现了spatial和channel之间的解耦,达到模型加速的目的,但是整个模型非常类似vgg,思想比较陈旧,最主流的做法应该是参考resnet设计思想,引入block和残差设计。
而且作者通过实验发现mobilenetV1结构存在比较大的缺陷。在实际使用的时候, 发现Depthwise 部分的kernel比较容易训废掉即训完之后发现depthwise训出来的kernel有不少是空的即大部分输出为0,这个问题在定点化低精度训练的时候会进一步放大。针对这个问题,本论文进行了深入分析。
假设经过激活层后的张量被称为兴趣流形(manifold of interest),shape为HxWxD。根据前人研究,兴趣流形可能仅分布在激活空间的一个低维子空间里,或者说兴趣流形是可以用一个低维度空间来表达的,简单来说是说神经网络某层特征,其主要信息可以用一个低维度特征来表征。一般来说我们都会采用类似resnet中的bottlenck层来进行主要流形特征提取,在具体实现上,通常使用1x1卷积将张量降维,但由于ReLU的存在,这种降维实际上会损失较多的信息,特别是在通道本身就必须小的时候。

如上图所示,利用MxN的矩阵T将张量(2D,即dim=2)变换到M(M可以任意设置)维的空间中,通过ReLU后(y=ReLU(Bx)),再用此矩阵T的逆恢复原来的张量。可以看到,当M较小时,恢复后的张量坍缩严重,M较大(30)时则恢复较好。这意味着,在较低维度的张量表示(兴趣流形)上进行ReLU等线性变换会有很大的信息损耗。显然,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后基本不会丢失太多的输入信息;相比之下如果原始输入维度只增加到2或3后再作为ReLU的输入,输出恢复到原始维度后信息丢失较多。因此在MobileNet V2中,执行降维的卷积层后面不会接类似ReLU这样的非线性激活层,也就是所提的linear bottleneck。总结如下:
- 对于ReLU层输出的非零值而言,ReLU层起到的就是一个线性变换的作用
- ReLU层可以保留输入兴趣流形的信息,但是只有当输入兴趣流形是输入空间的一个低维子空间时才有效。
如果上述不好理解的话,那么通俗理解就是:当采用1x1逐点卷积进行降维,如果原始降维前输入通道本身就比较小,那么经过Relu层后会损失很多信息,导致不断堆叠层后有效信息越来越小,到最后分类性能肯定会下降,就会表现出很多kernel出现全0的现象,特别是逐深度卷积+1x1逐点卷积时候现象更加明显,因为逐深度卷积表达能力不如标准卷积。
Linear Bottlenecks
基于上述分析,为了保证信息不会丢失太多,在Bottlenecks层的降维后不在接relu,图示如下:
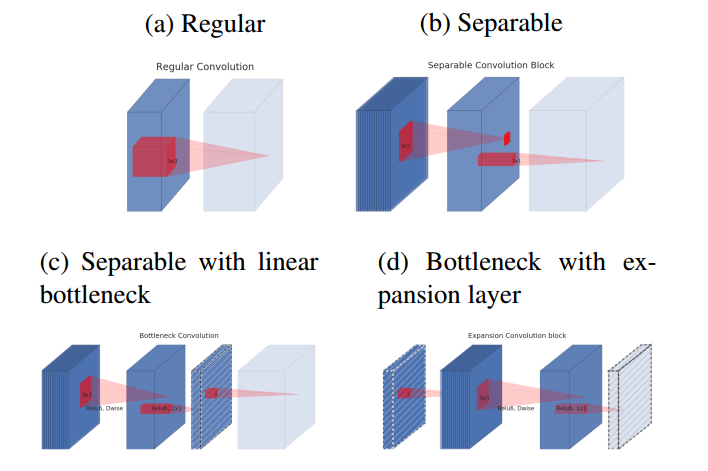
蓝色块表示特征图,浅色块表示下一个block的开始,红色块表示卷积或者Relu操作,含有斜线的块表示不包括非线性层
- (a)为标准卷积
- (b)为逐深度可分离卷积
- (c)为在(b)后面加入“bottlenck layer”,即在后面接了一个不含有relu层的1x1卷积进行通道扩张,防止信息丢失过多
- 考虑到block是互相堆积的,调整一下视角,将“bottlenck layer”看成block的输入,那么这种结构也等价于(d),block中开始的1x1卷积层称为“expansion layer”,它的通道大小和输入bottleneck层的通道大小之比,称为扩展比(expansion ratio)。扩展层之后是depthwise卷积,然后采用1x1卷积得到block的输出特征,这个卷积后面没有非线性激活
Inverted residuals
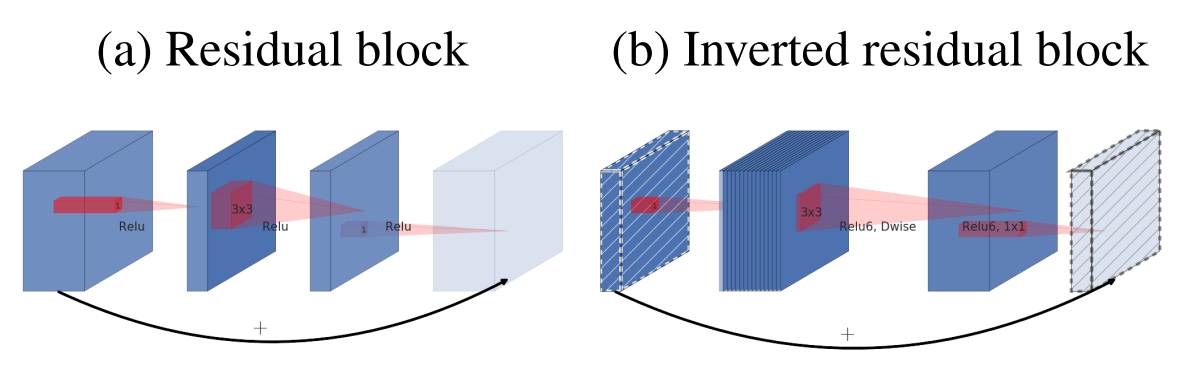
(a)为标准的残差块,而(b)为所提出的反转残差块,为啥叫做反转?原始是残差块一般先采用bottleneck layer(1x1卷积)进行降维,最后在采用bottleneck layer进行扩展,而反转的做法是先采用bottleneck layer(1x1卷积)进行升维,最后在采用bottleneck layer进行降维,是相当于残差块的反向操作,其中斜线块表示在该特征图上面没有采用relu激活函数,通过实验表明反转残差块可以在实现上减少内存的使用,并且精度更少。
请注意:上图(b)应该是绘制错误,论文里面说过在1x1降维层不采用relu激活函数,故实际上应该是1x1conv升维度(有relu)+3x3d conv+1x1conv降维(没有relu),但是上面图明显绘制错误了。通过下面图示也可以看出来:
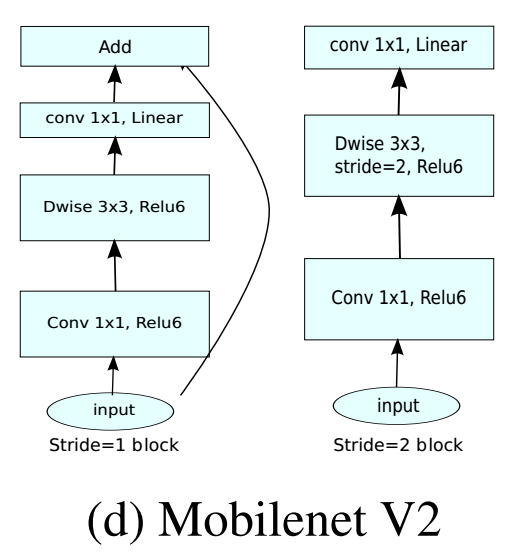
总结
mobilnetv2主要是对v1进行针对性改进,针对dwconv+pwconv后经过relu激活层会丢失大量信息,导致dw很多kernel都失活,提出了线性瓶颈层,主要是pw卷积降维时候不采用relu,接着在该基础上结合残差设计思想提出了反转残差块,通过堆叠反转残差块实现了在移动端上又快又好的模型。多个任务benchmark平台结果表明比mobilenetv1和shufflenetv1更加优异。